[LG]《Trading-R1: Financial Trading with LLM Reasoning via Reinforcement Learning》Y Xiao, E Sun, T Chen, F Wu... [University of California, Los Angeles & University of Washington] (2025)
Trading-R1 是一款专为金融交易设计的大型语言模型,结合了结构化推理与强化学习,实现了专业交易分析与决策的高度融合。其核心亮点包括:
• 数据驱动:基于Tauric-TR1-DB,涵盖14支大盘股、18个月多模态财务数据,构建10万条高质量训练样本,确保模型理解真实市场动态。
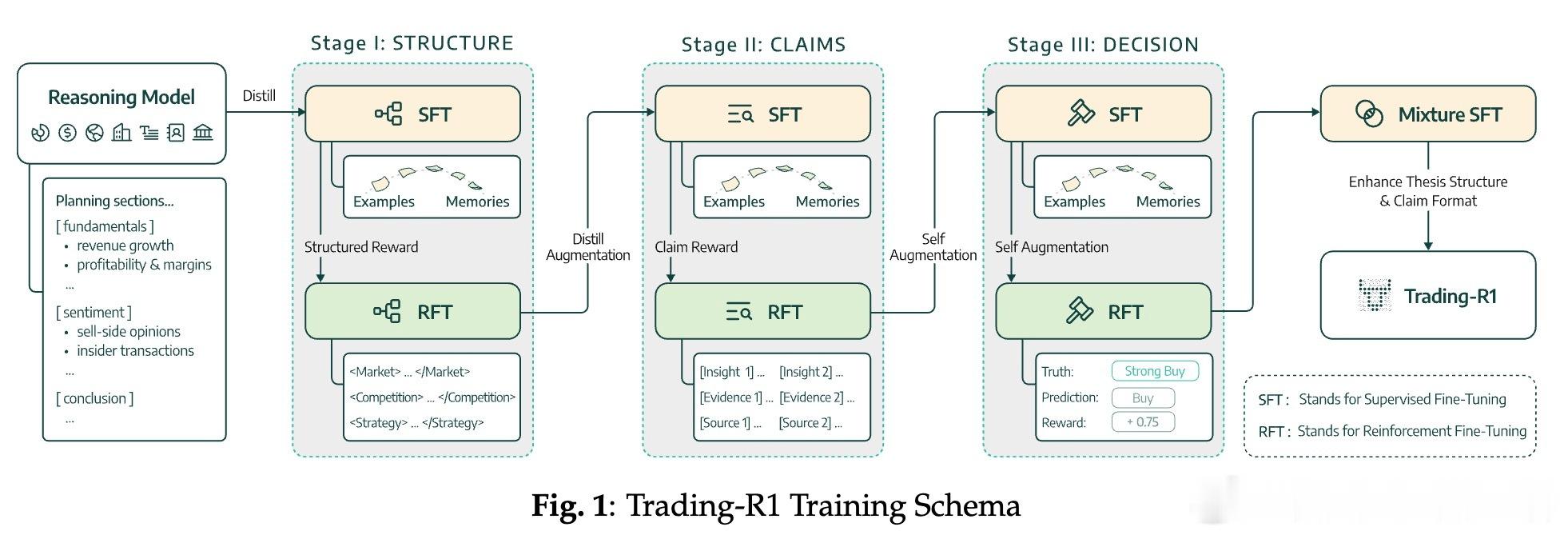
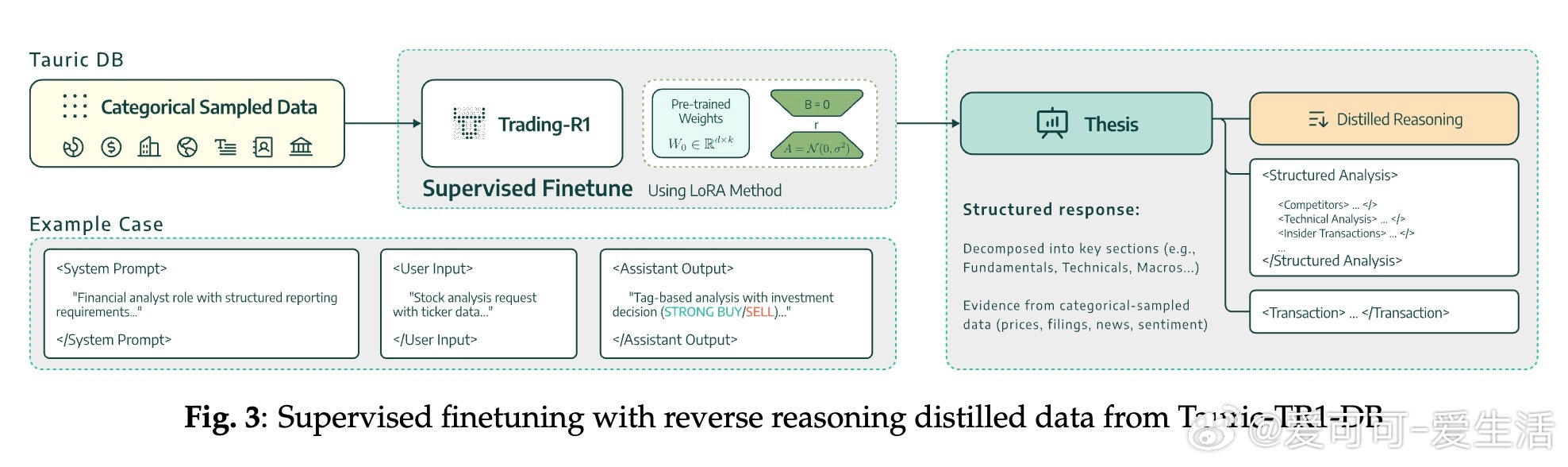
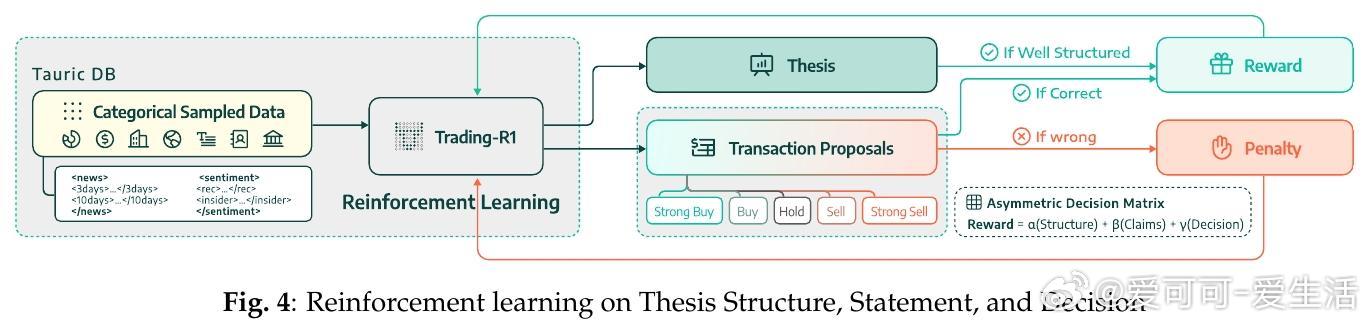
• 三阶段训练:采用结构化思维 → 证据支持 → 市场决策的递进式训练,先通过监督微调构建严谨投资论述,再用强化学习对交易信号进行风险调整优化。
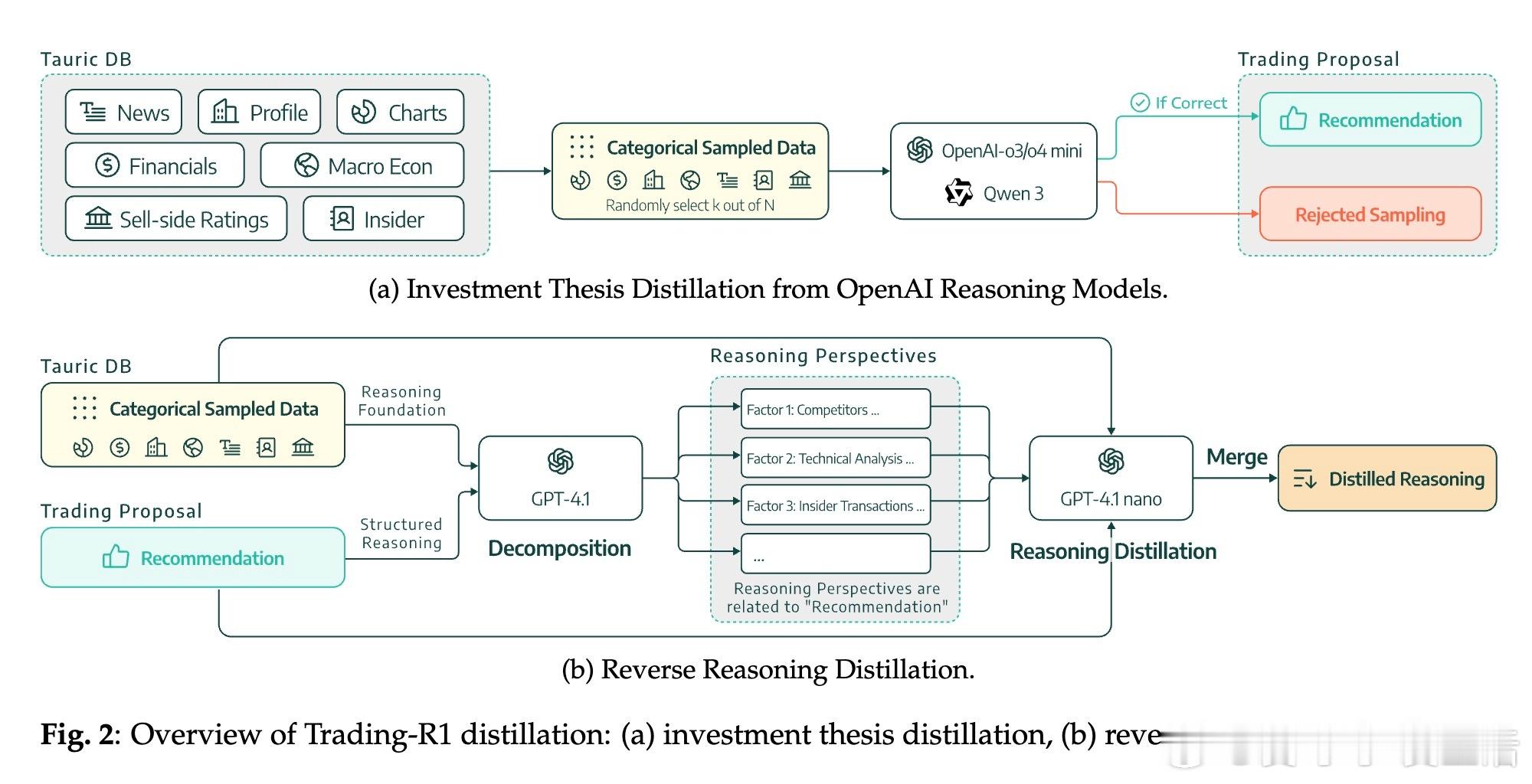
• 逆向推理蒸馏:创新性地从商业黑箱模型中重构完整推理链,解决了缺乏中间推理过程标签的难题,提升模型的解释性和可信度。
• 波动率调整标签:通过多时间窗收益归一化,设计非对称奖惩机制,体现市场风险偏好和牛熊周期,实现金融决策的稳健性。
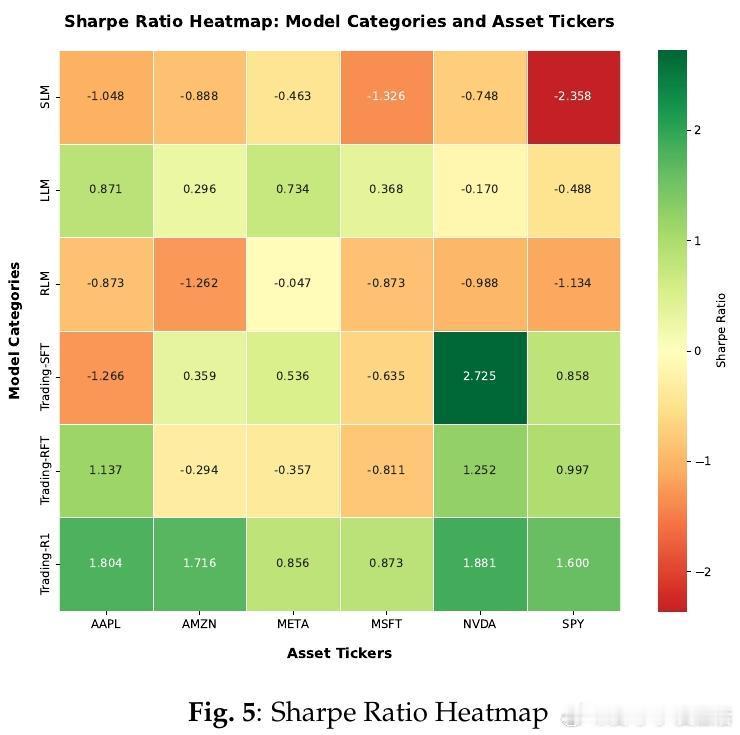
• 优异表现:在多只标的资产及ETF上,Trading-R1超越通用LLM及强化学习模型,展现了更高的夏普率、收益率及命中率,同时最大回撤更低。
• 实用价值:生成结构化、事实支撑的投资论述,方便专业人士理解和定制,支持本地部署保护数据隐私,适合卖方研究、买方决策及数据供应商应用。
心得:
1. 金融交易决策的复杂性远超通用任务,需兼顾数据质量与推理稳定性,单纯延长链式思考反而增加错误累积。
2. 分阶段训练策略有效避免监督与强化学习目标冲突,保障模型既能产出专业分析,又能做出市场适应性强的交易决策。
3. 结构化输入与输出设计提升了模型在长上下文中的表现,解决了信息噪声大、数据异构性强的行业难题。
论文详情🔗
详细介绍🔗: github.com/TauricResearch/Trading-R1
金融科技大语言模型强化学习结构化推理量化交易