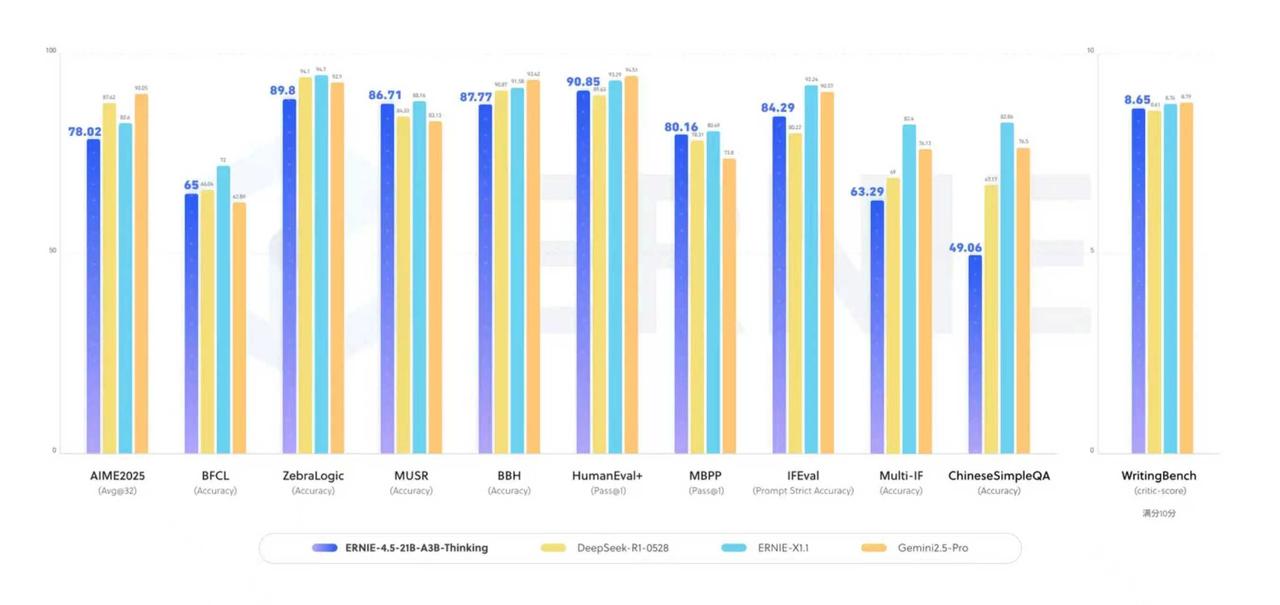
双榜登顶!文心思考模型ERNIE-4.5-21B-A3B-Thinking 霸榜HuggingFace,揭示AI竞争新逻辑! 210亿参数仅激活30亿,中国模型以效率革命引领AI发展新方向。 全球AI竞争正在换轨:从拼参数规模到拼计算效率。百度文心思考模型ERNIE-4.5-21B-A3B-Thinking以总参数210亿、激活仅30亿的轻量化设计,成功登顶HuggingFace 全球模型总趋势榜和文本模型趋势榜。 这一成功不仅展现了模型本身的性能,更体现了其背后的技术生态优势。目前全球主流顶尖大模型大多依赖PyTorch等开源框架训练,而能够依托自研框架跑通顶级模型的厂商,只有谷歌和百度。 AI发展正在从“大力出奇迹”转向“精细化管理”。百度文心模型采用混合专家(MoE)架构,总参数规模21B,每个token仅激活3B参数。在部署上,MoE的出现不仅优化了LLM的架构,适配多种模型框架,也能够做到「轻量化」的管理和调用,字如其名,属于名副其实的「专家」。 这种设计实现了计算效率的质的飞跃,打破了“参数规模决定模型能力”的传统认知。以轻量级规模实现了接近SOTA的智能表现,为AI普及奠定了坚实基础。尽管是轻量化模型,但ERNIE-4.5-21B-A3B-Thinking在多项评测中展现出接近业界顶尖大模型的表现。它在逻辑推理测试中得分较前代提升27%,数学问题解决准确率提高31%,科学知识应用能力增长19%。 不仅如此模型还支持128K的上下文窗口,适用于需要长上下文的复杂推理任务。这种全面能力使得轻量化模型同样能够胜任复杂任务。 中国AI技术发展的独特路径正在形成:不同于西方科技公司普遍采用的“大而全”策略,中国研究者通过架构创新实现了“小而精”的突破。同时,这也表明了:AI竞争正在从技术单点突破转向全栈生态竞争。