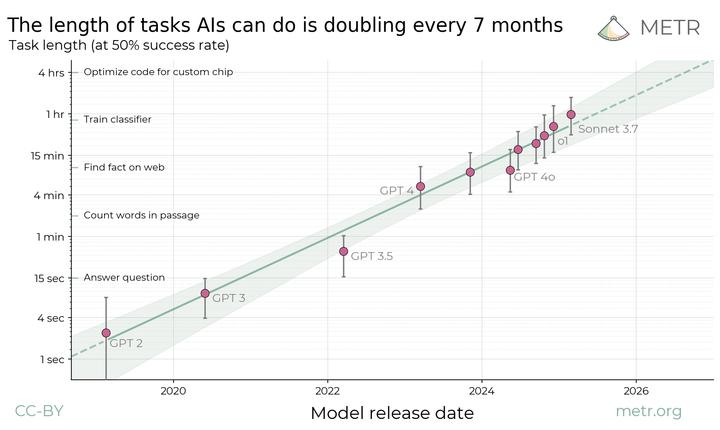
数据才是LLM发展的核心驱动力? 科技博主Jack Morris提出了一个挺有意思的观点:真正推动AI性能提升的,可能不是算法架构本身,而是被解锁的海量数据。 具体是怎么回事呢?咱们一起来看看Jack Morris的这篇博客的重点提要: 一、AI发展的四大范式突破 当我们回顾AI发展的四大范式突破,每一次所谓的“新”架构,其实都是解锁了新的大规模数据源: 深度神经网络(DNNs)(2012,AlexNet)→ 解锁 ImageNet 等图像数据。 Transformer + LLMs(2017,《Attention Is All You Need》)→ 解锁互联网文本数据。 RLHF(人类反馈强化学习)(2022,InstructGPT)→ 解锁“优质文本”数据。 推理能力(2024,如 OpenAI O1、DeepSeek R1)→ 解锁可验证数据(如计算器、编译器)。 这些突破很多时候都是在老技术(比如监督学习、强化学习)上做的文章,但核心点都在于找到了新的数据源。 一旦有了新数据,大家就疯狂地研究,怎么把数据榨干,或者用新方法更有效率地利用现有数据。 二、数据才是AI能力真正的推手 就算当年没发明AlexNet,可能也会有别的算法能搞定ImageNet;就算没有Transformer,我们可能也会用LSTM或者SSM,或者别的办法从网上那些海量数据里学东西。 我们一直在努力改进算法、优化模型结构、调整各种参数,但真正让AI能力突飞猛进的,往往是数据的变化。 举个例子:有研究者尝试用非Transformer架构开发类似BERT的模型。他们花了大约一年时间,对架构进行了数百次调整,最终开发出一种状态空间模型(SSM)。 当使用相同数据训练时,这种模型的性能与原始Transformer相当。 这一发现意义深远,因为它可能告诉了我们一个残酷的事实:从特定的数据集里能学到的知识,是有上限的。 不管你算法多花哨,模型多先进,数据能提供的信息量就是那么多,不会变多。 三、下一个范式转变从何而来? 很明显,AI的下一次突破,不会是哪个强化学习的新玩法,也不是哪个炫酷的新神经网络。它会来自那些还没被开发或没被充分利用的数据源。 现在大家都在盯着的一个“大宝藏”就是视频。YouTube每分钟上传约500小时的视频,远超整个互联网的文本总量。 视频里可不光有文字,还有说话的语气、物理世界的互动、文化信息,比纯文本丰富多了! 可以预见,一旦模型效率或算力足够,Google一定会开始用YouTube数据训练模型。 另一个潜在的“下一个大范式”是具身化数据收集系统,简单说就是机器人。 目前我们还没法有效地处理摄像头和传感器采集到的数据,让它们能被GPU训练。但如果能开发出更智能的传感器或者提升计算能力,这些数据就能派上大用场了。 虽然现在我们都沉浸在语言模型的浪潮里,但实话实说,语言数据也快被“榨干”了。 如果想推动AI进步,或许我们该停止寻找新算法,转而寻找新数据。 对此,你怎么看?

![层层转包后发现竟是中国产品贴牌?[捂脸哭]韩国爆了个大新闻:LG开发的AI护理](http://image.uczzd.cn/1831726989034027881.jpg?id=0)