[LG]《Scaling up Multi-Turn Off-Policy RL and Multi-Agent Tree Search for LLM Step-Provers》R Xin, Z Zheng, Y Nie, K Yuan... [ByteDance Seed] (2025)
BFS-Prover-V2:突破自动定理证明的训练与推理双重瓶颈
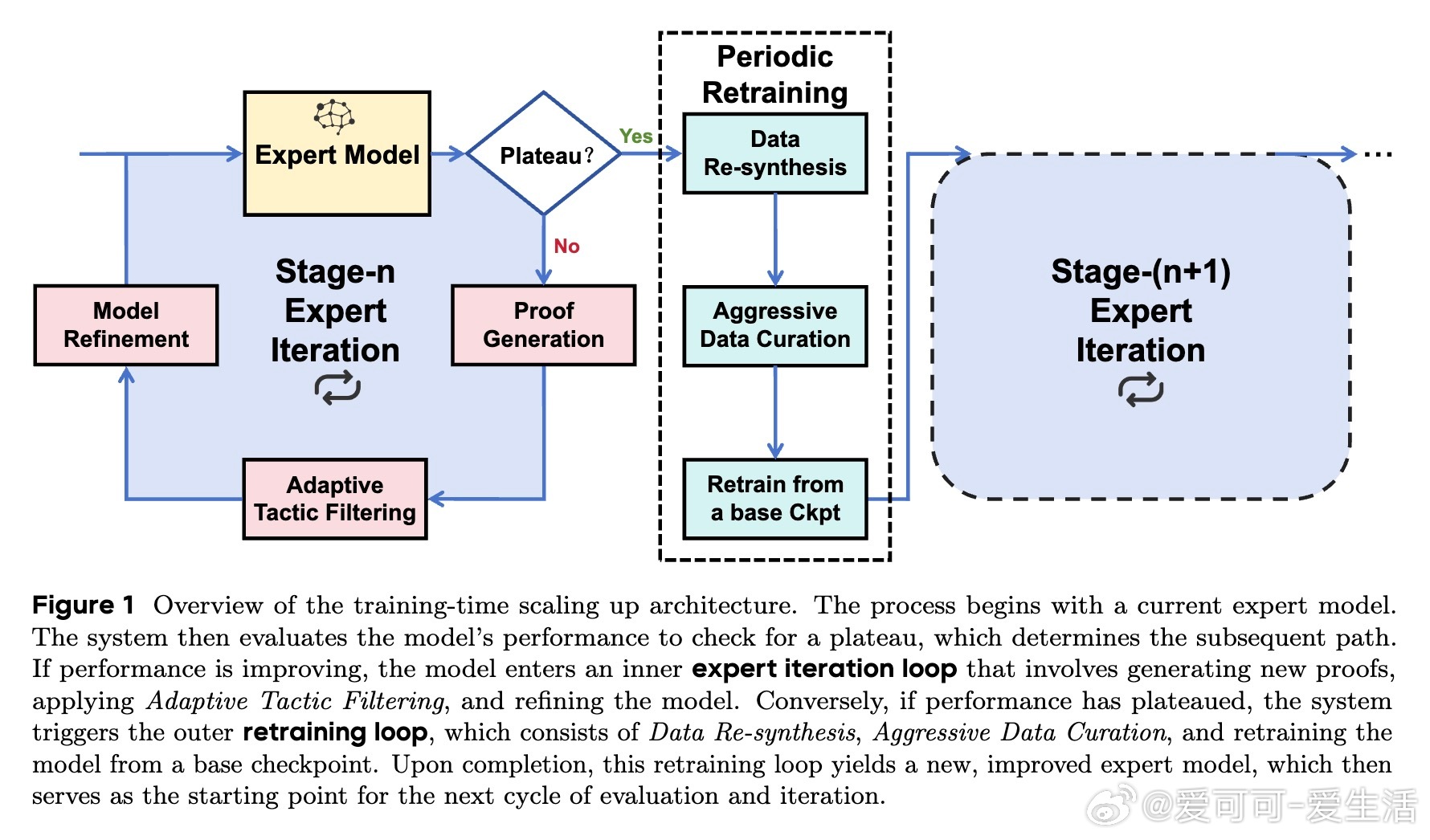
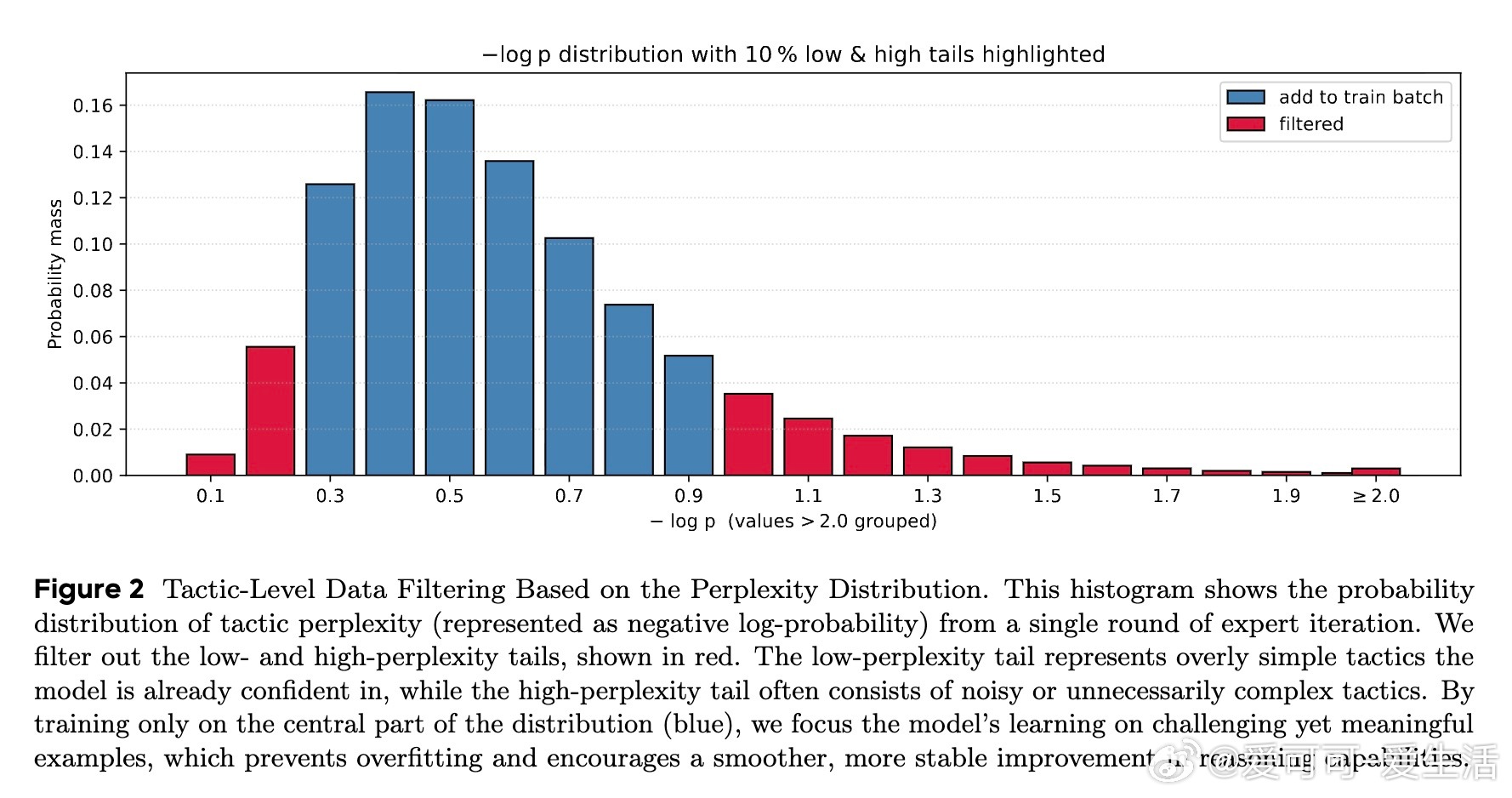
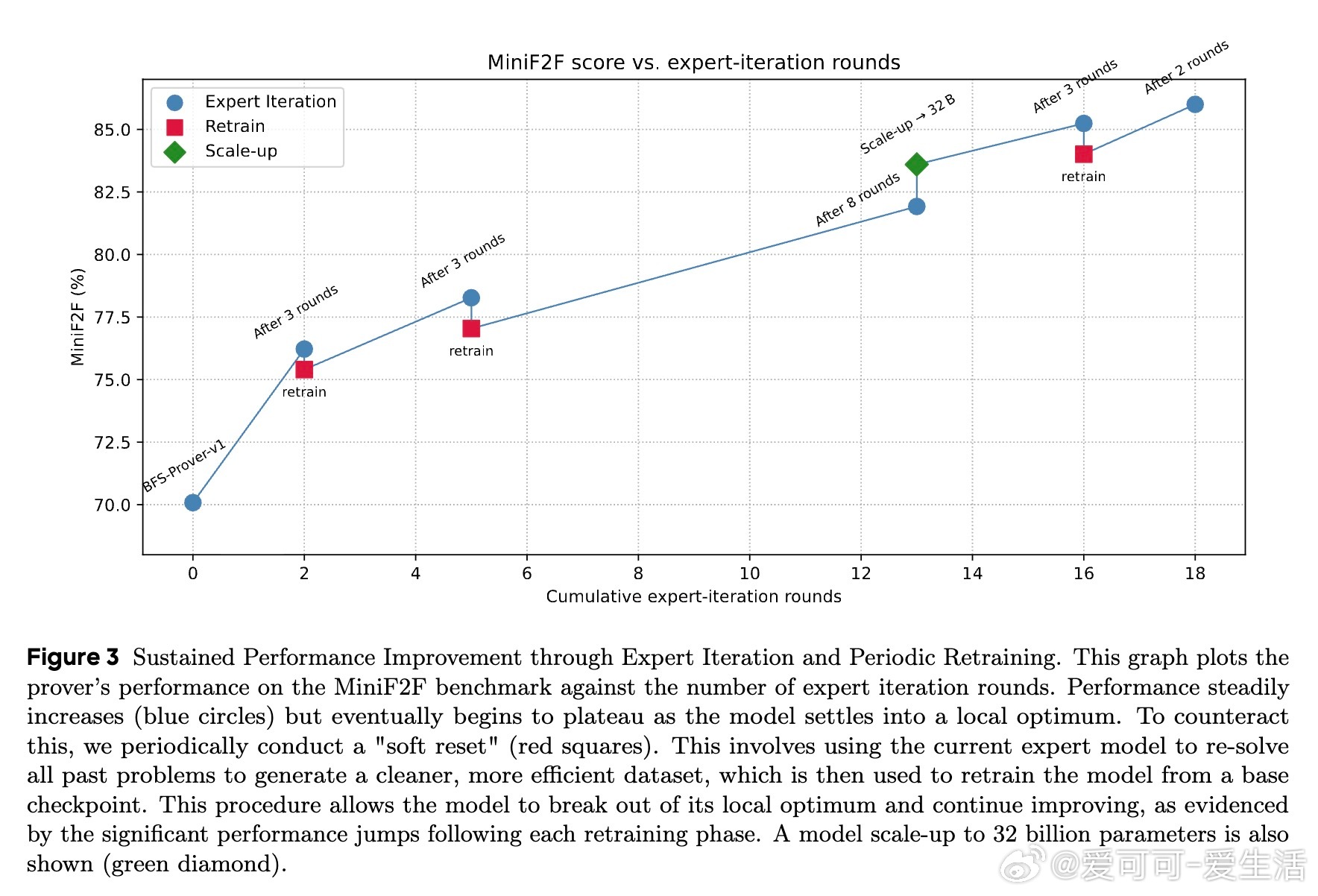
• 创新训练框架:采用多回合离策略强化学习(off-policy RL)结合多阶段专家迭代,运用基于困惑度(perplexity)的动态策略级数据过滤与周期性重训练,有效破解性能平台期,实现长期持续提升。
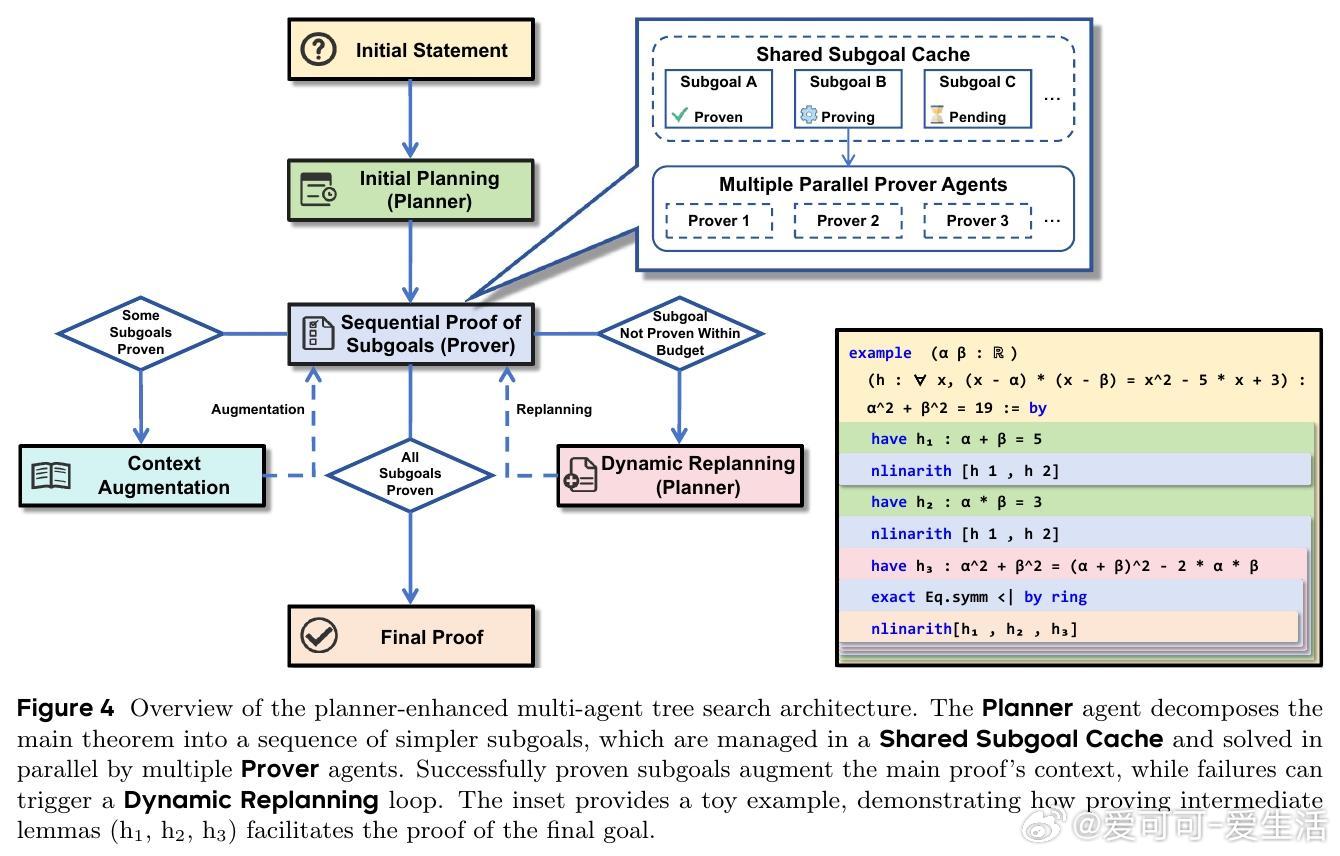
• 推理架构升级:引入基于通用推理模型的规划器(Planner)增强多智能体并行树搜索,层次化将复杂定理分解为可管理子目标,利用共享子目标缓存协同加速搜索,解决指数级搜索空间爆炸。
• 训练规模与数据量:基于约300万自动形式化数学问题,结合Qwen2.5系列大模型,训练策略灵活切换微调与重训练,批量达1024,保证模型稳定收敛。
• 实验突破:在MiniF2F高中竞赛数学测试上达95.08%准确率,ProofNet本科级库测试达41.4%,显著超越现有LLM步进证明器,达到最先进水平。
• 证明风格优势:步骤级交互式证明显著缩短证明长度,能发现更简洁、创新的证明策略,体现对数学库高阶定理的有效利用,虽可读性较整体生成略低但效率与能力提升明显。
• 体系通用价值:训练与推理技术适用于需长程多轮推理及复杂搜索的其他领域,具备广泛应用潜力。
心得:
1. 动态困惑度过滤自动调节训练难度,避免简单过拟合与复杂噪声干扰,保证模型始终在能力边界高效学习。
2. 周期性重训练机制如“软重启”,有效跳出局部最优陷阱,激活模型探索潜力,实现性能多次跃升。
3. 分层规划与多智能体并行协作,成功将复杂逻辑推理任务拆解为可控子问题,极大提升推理效率与可扩展性。
详情🔗 arxiv.org/abs/2509.06493
人工智能强化学习自动定理证明大语言模型多智能体系统数学推理