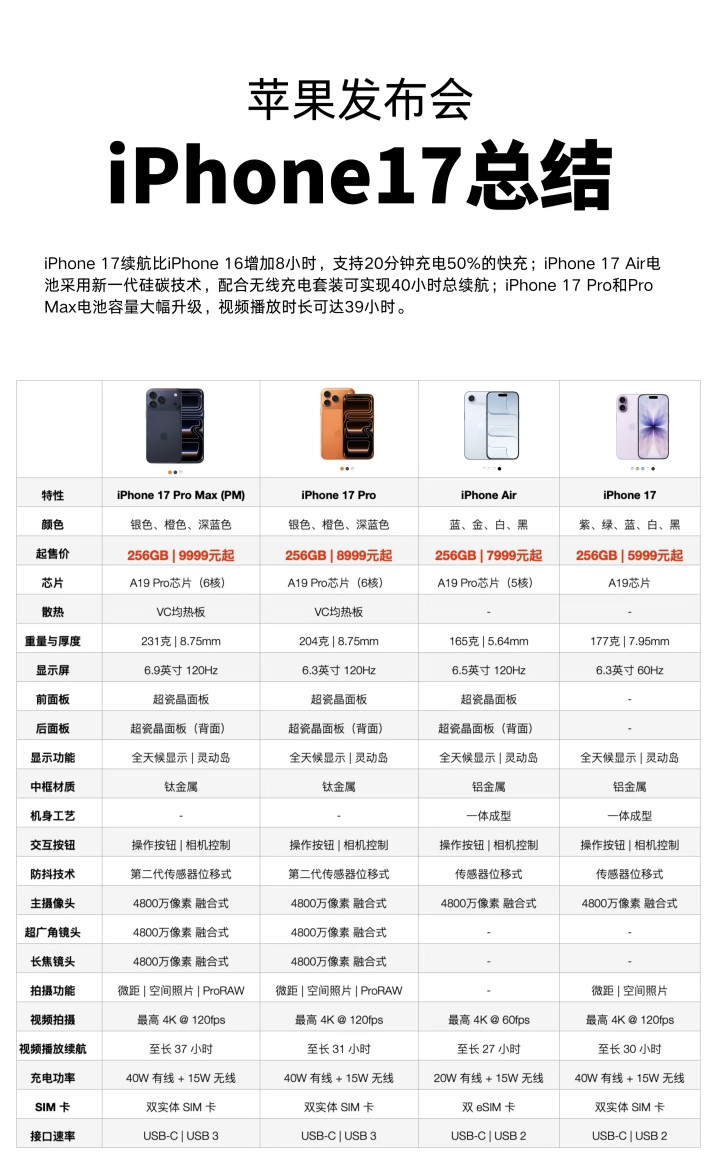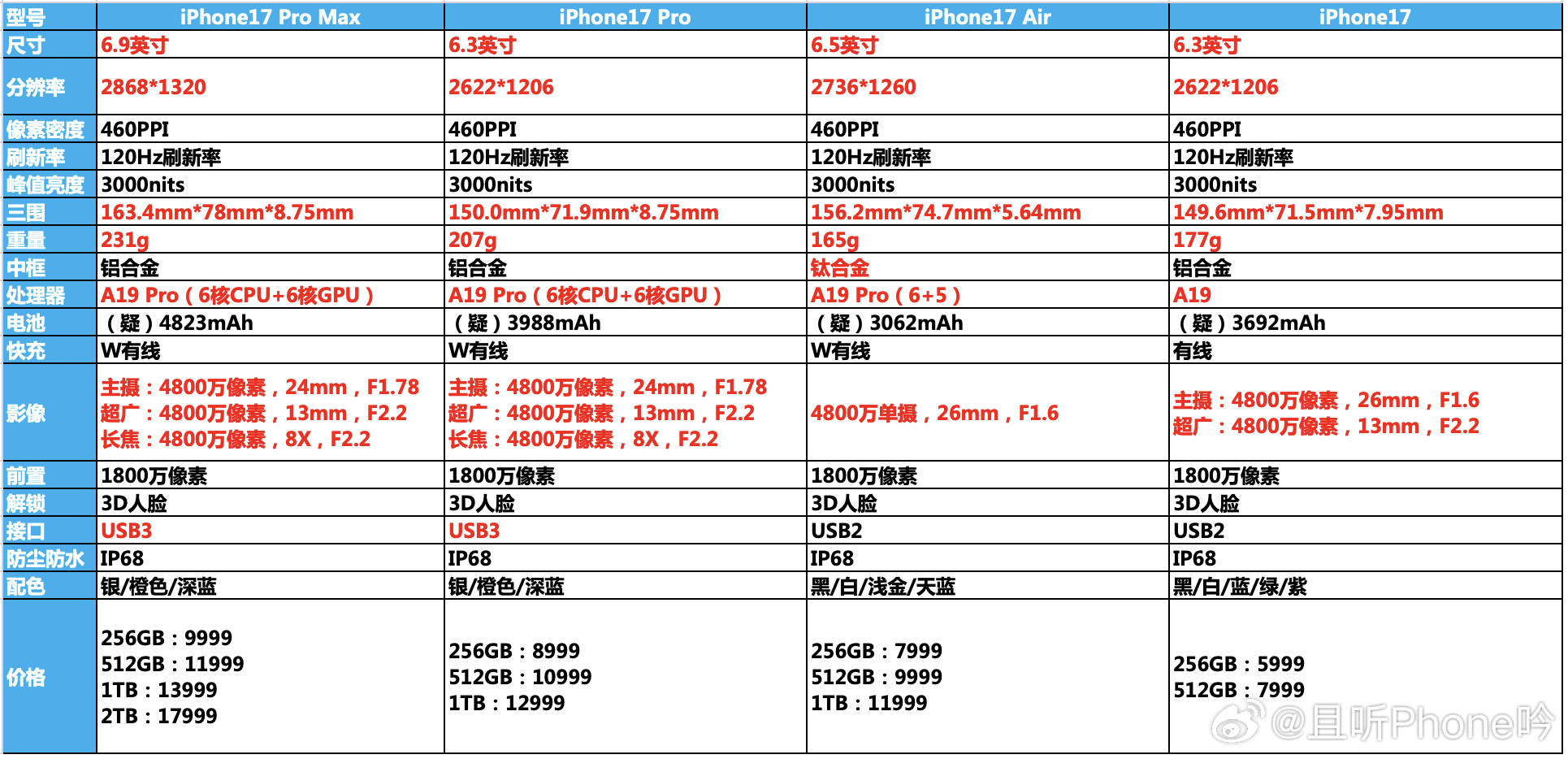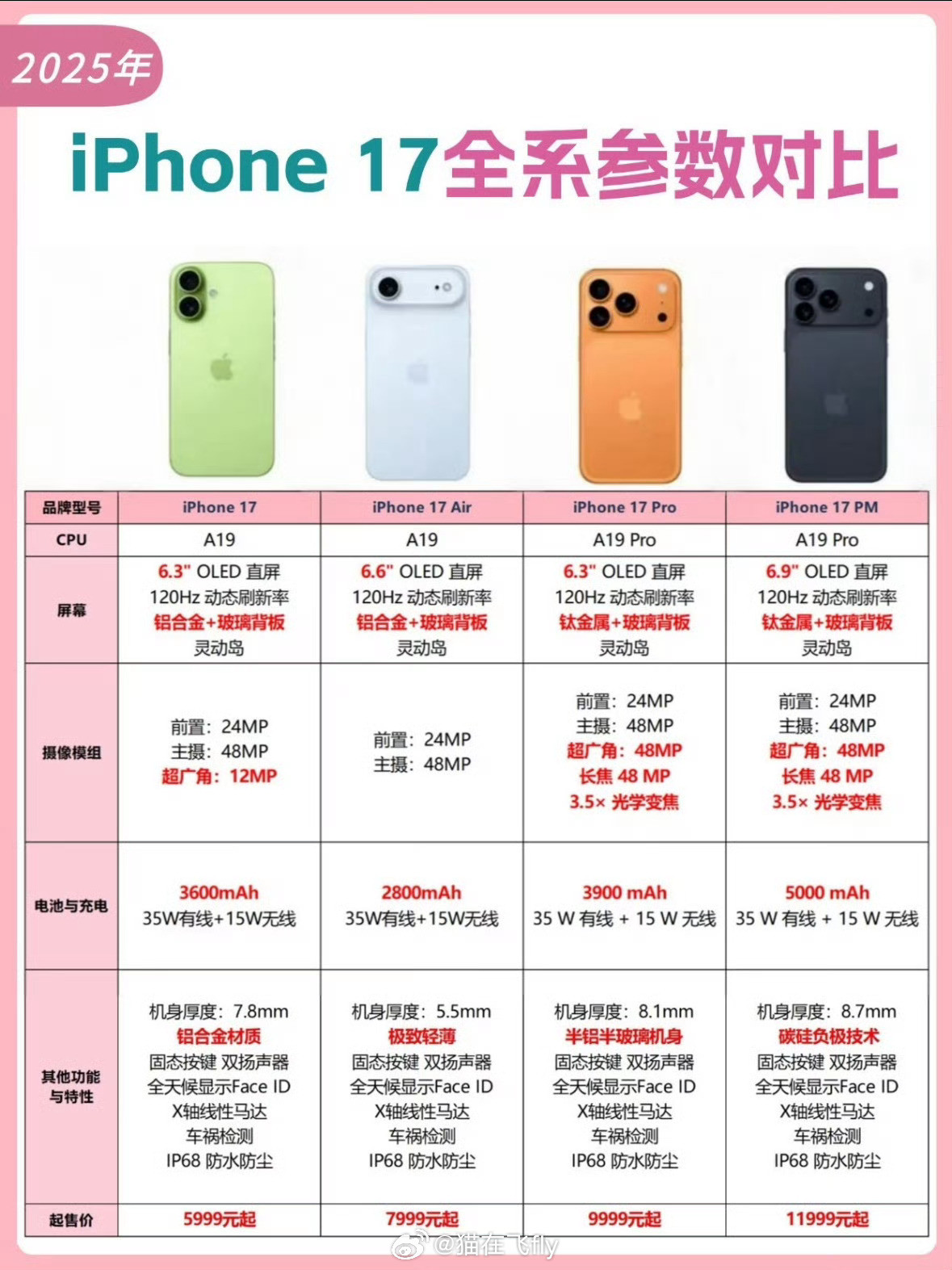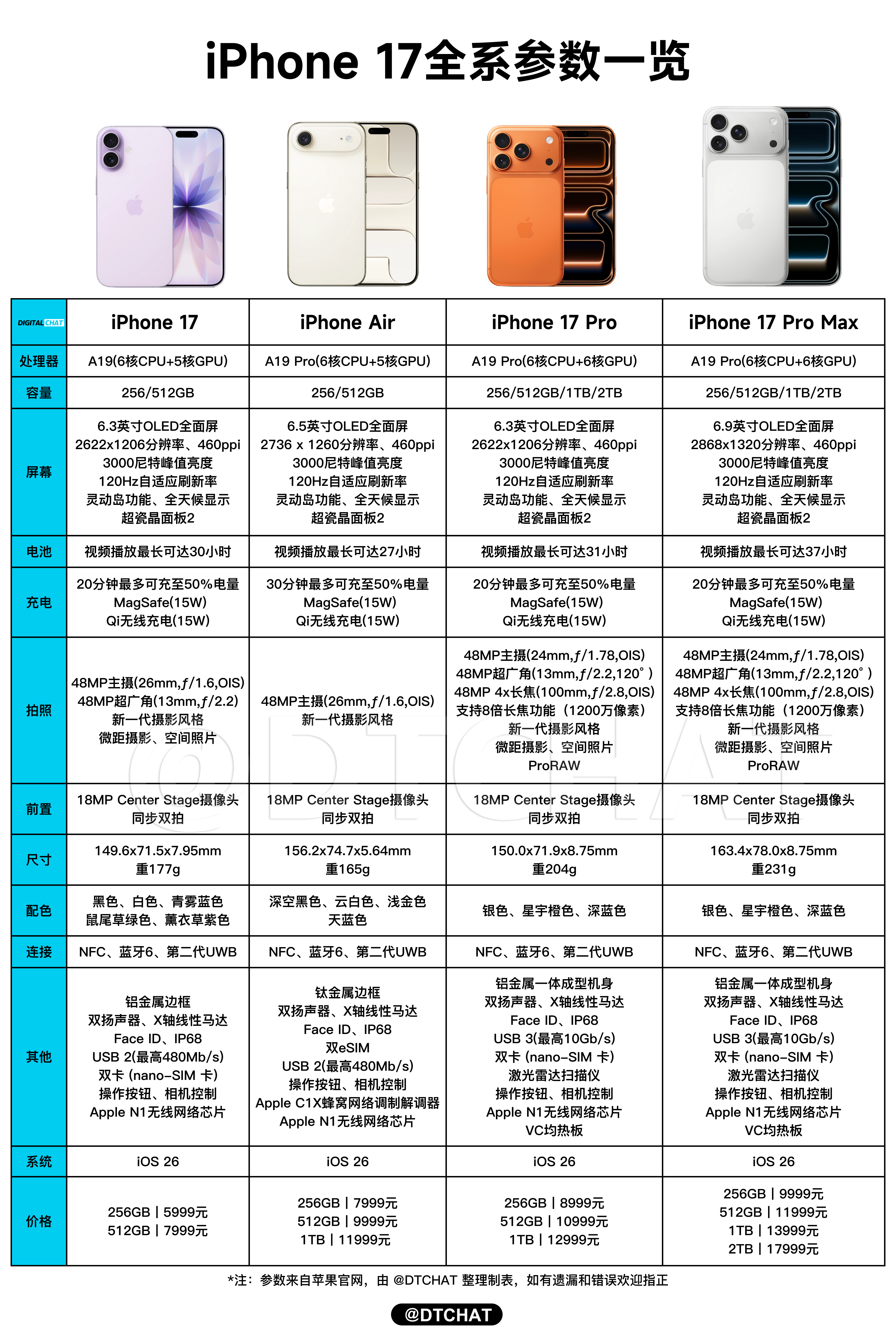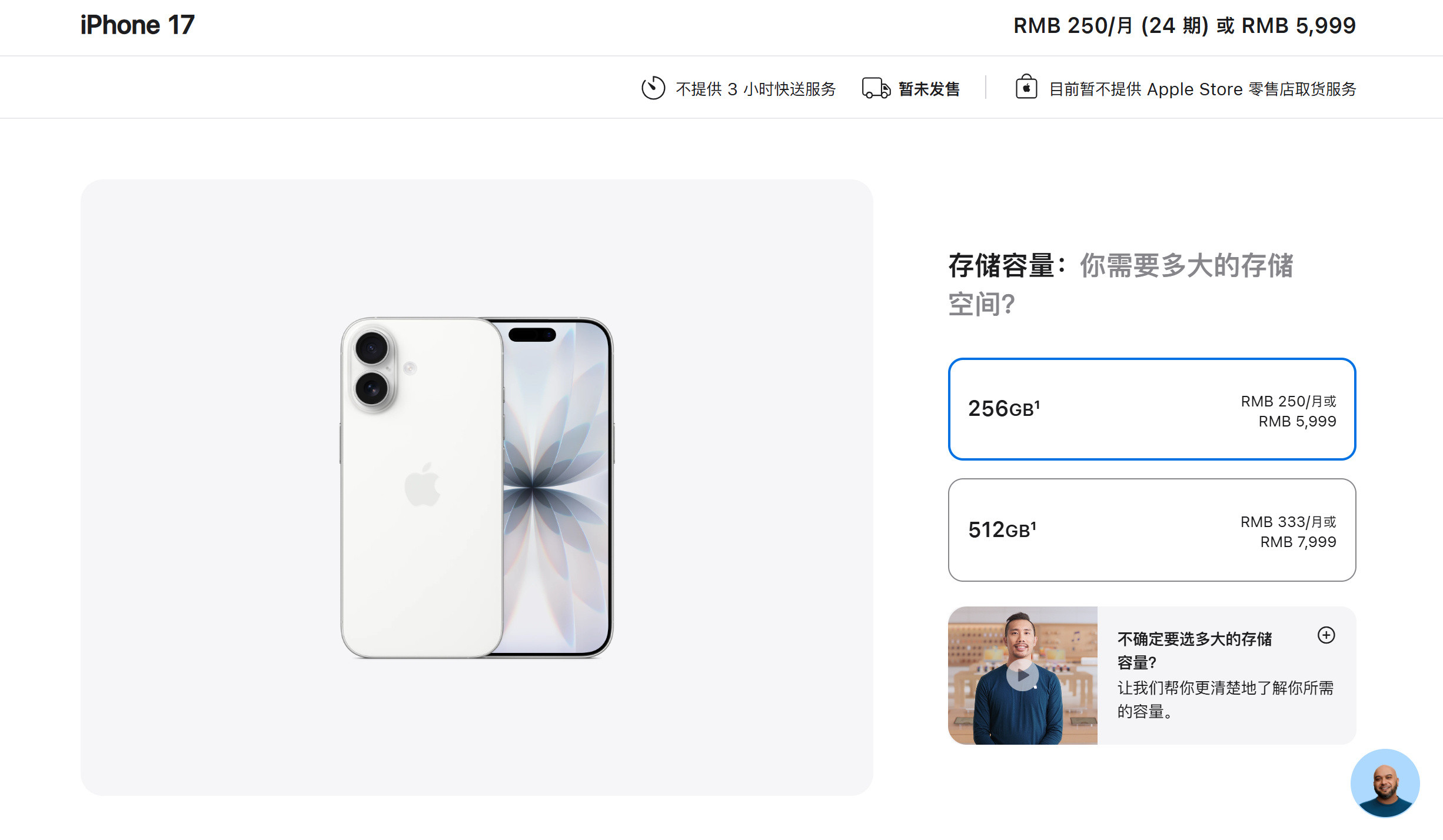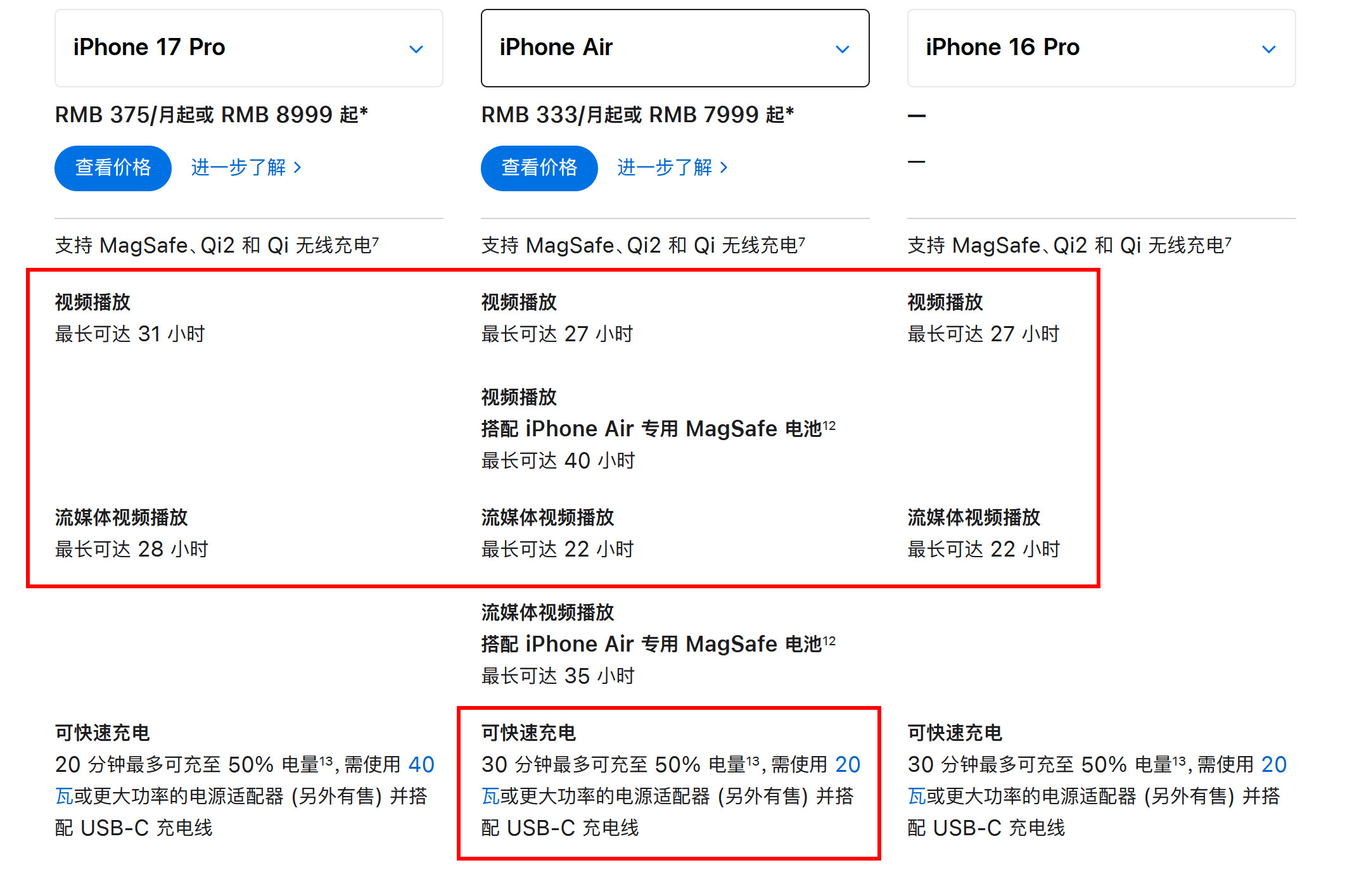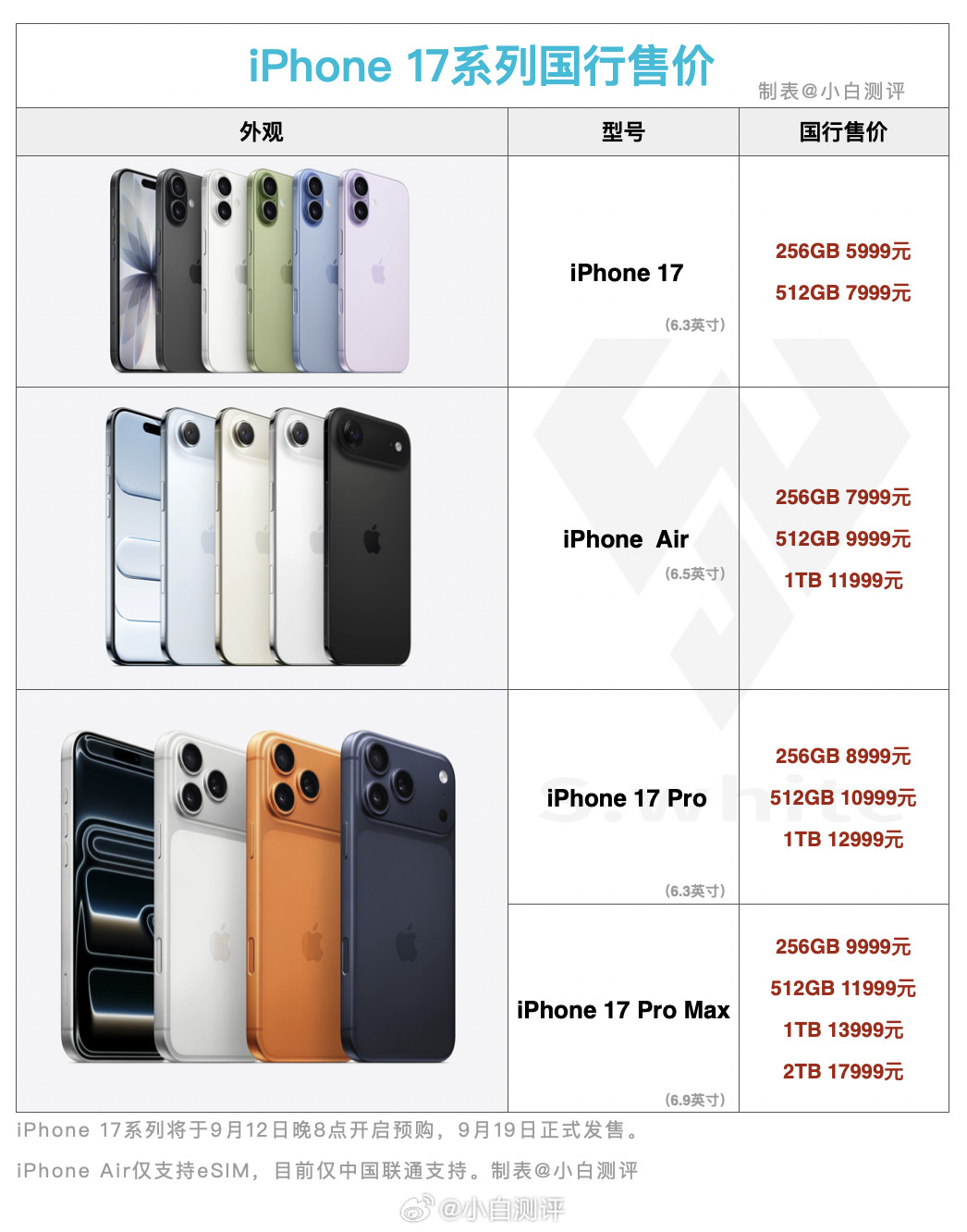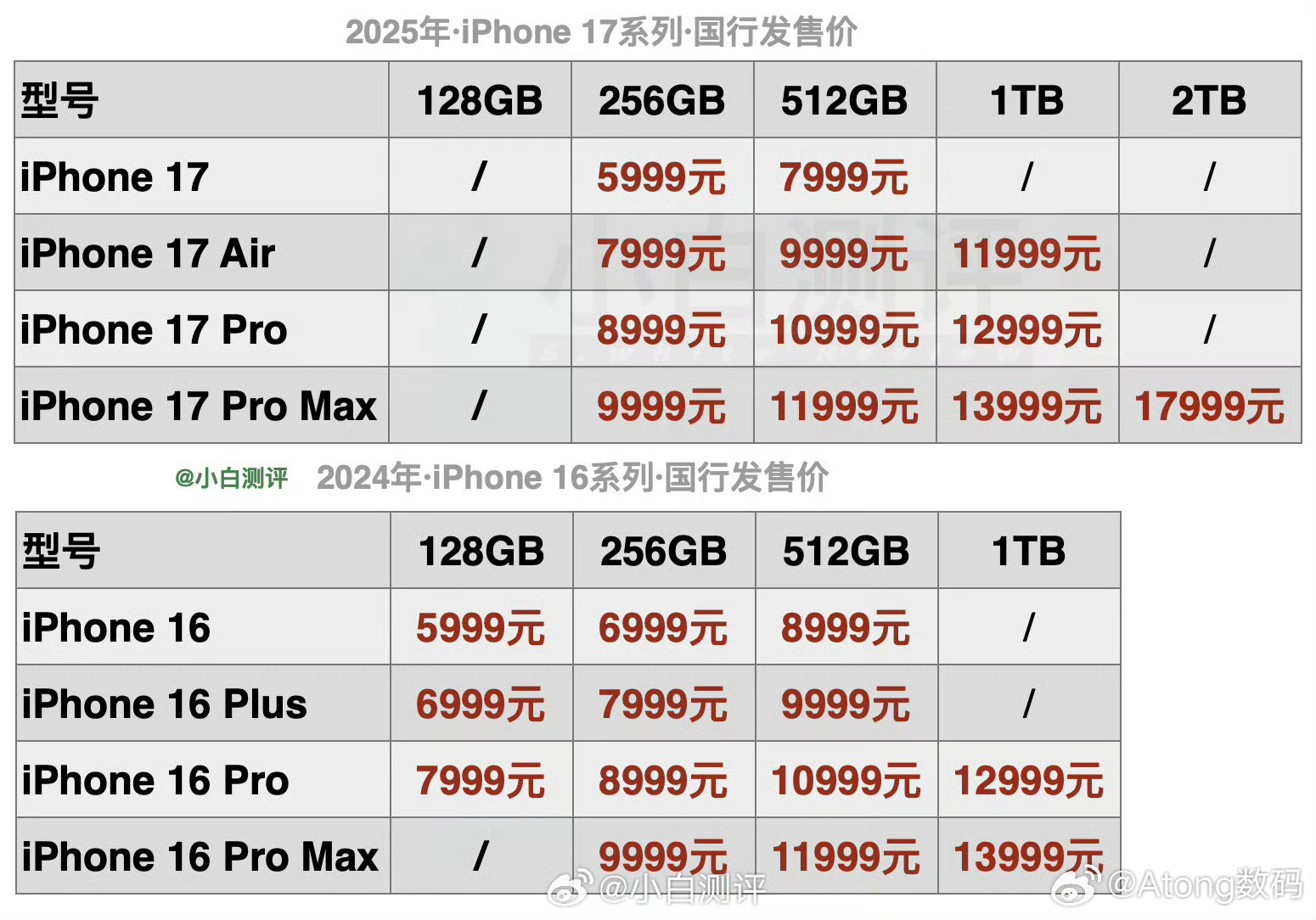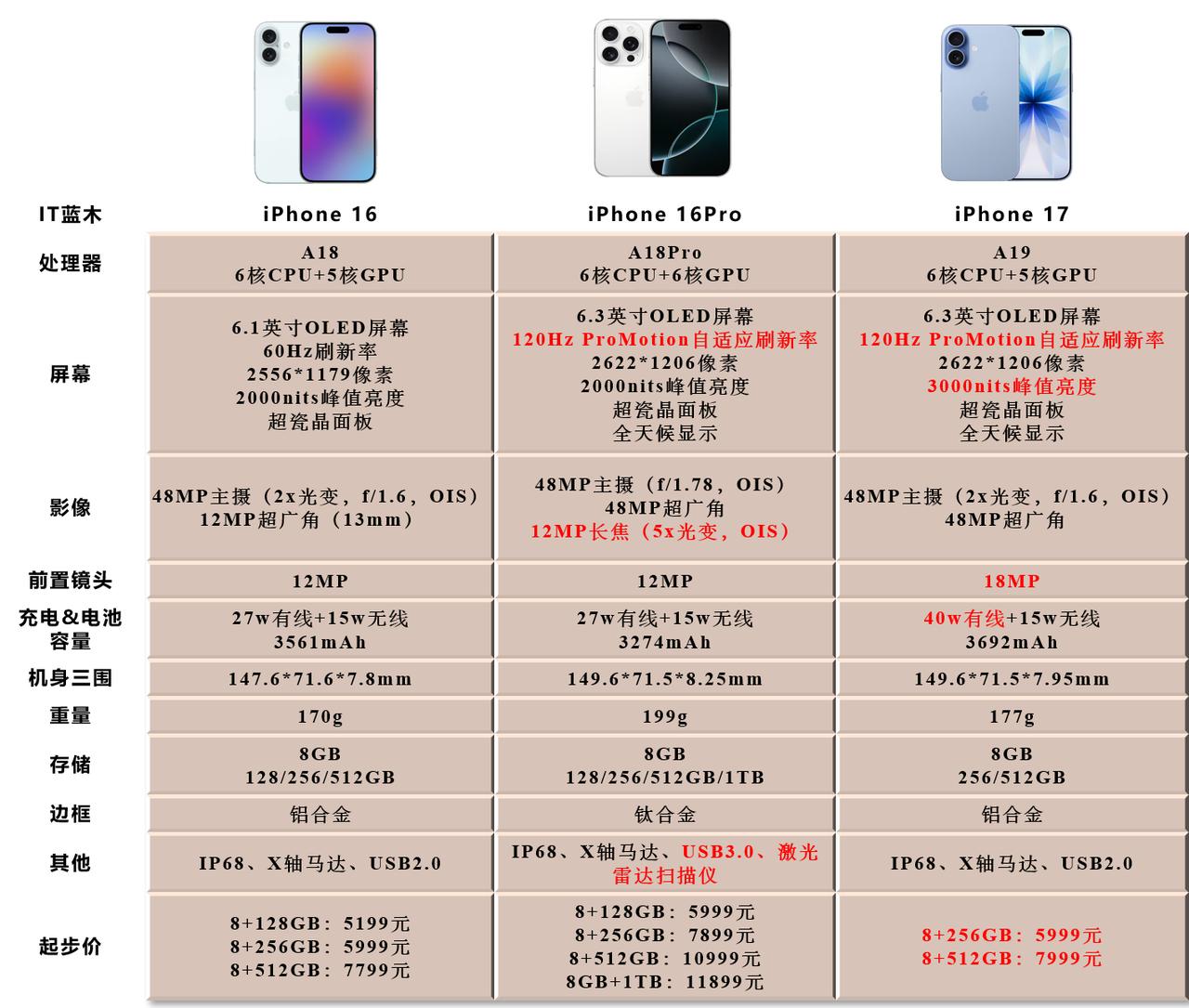
iPhone17标准版对比16和16Pro,升级确实大这次17标准版最大的
iPhone17标准版对比16和16Pro,升级确实大这次17标准版最大的升级就是屏幕,支持1-120Hz自适应刷新率,超广角升级到了48MP,前置升级到18MP,影像升级也很大。另外iPhone17的性能、充电、续航也是全面升级,内存直接256GB起步(这个杀伤力最大,相当于变相降价1000元),另外5999元的价格还支持国补,相当于新款iPhone只需5499元。标准版香,实在是香!