
大模型扎堆更新,AI大战风暴将至
最近这段时间,大模型领域又出现了爆发式更新。
各大科技巨头纷纷亮出自己的王牌,大模型的更新如同雨后春笋般涌现,一场关于智能、效率和成本的较量即将拉开帷幕。
百度在上周的Create 2025大会上可谓是动作频频,风头无两。
百度创始人李彦宏高调宣布开源文心4.5系列,并毫不避讳地直指DeepSeek“慢又贵”。在他的介绍下,百度的新模型在性能和成本上才是真正实现了质的飞跃。

图源:微博
事实上,在过去的一个月中,百度已经连续发布了多款大模型,例如文心大模型4.5 Turbo、深度思考模型X1 Turbo……
其中,文心4.5 Turbo模型在多模态基准测试成绩上已经追平了DeepSeek,并且还在API调用价格方面做到了DeepSeek的40%,详细的介绍可以去看上一篇《李彦宏炮轰DeepSeek,百度AI才是未来》。

图源:小红书
而就在今天凌晨,阿里巴巴紧随其后,发布了新一代通义千问模型Qwen3。
阿里云方面宣称,Qwen3是国内首个“混合推理模型”,将“快思考”与“慢思考”集成进同一个模型,参数量仅为DeepSeek-R1的三分之一,但性能却全面超越了R1以及OpenAI的o1等全球顶尖模型。这一消息无疑再次让科技圈为之震动。
据官方介绍,Qwen3采用了混合专家(MoE)架构,总参数量达到235B,但激活仅需22B,预训练数据量高达36T。
通过多轮强化学习,Qwen3将非思考模式无缝整合到思考模型中,实现了简单需求的低算力“秒回”和复杂问题的多步骤“深度思考”。
这种“推理/非推理”二合一的设计,不仅提升了模型的智能水平,还大幅降低了算力资源消耗。

图源:观察者网
并且在性能方面,Qwen3在推理、指令遵循、工具调用、多语言能力等多个维度都创下了新的纪录。
例如,在奥数水平的AIME25测评中,Qwen3斩获81.5分,刷新了开源纪录;在代码能力测试中,Qwen3也表现不俗,突破了70分大关……
此外,如前文所说,Qwen3的部署成本极低,仅需4张H20显卡即可部署满血版,显存占用仅为性能相近模型的三分之一。
阿里云还提供了丰富的模型版本,从30B到235B的MoE模型,再到0.6B到32B的密集模型,每款模型都实现了同尺寸开源模型的最佳性能。

图源:观察者网
与此同时,OpenAI也在悄然发力。
近日,OpenAI又一次更新了GPT-4o模型,其CEO奥特曼亲自介绍,更新后的GPT-4o在智力和个性方面有了显著提升。
更新后的模型不仅优化了记忆保存时间,还增强了在STEM领域的问题解决能力。新GPT-4o还在响应方式上进行了改进,能够更主动地引导对话,输出更有效的结果。

图源:X平台
另一方面,根据数据显示,目前GPT-4o在LMArena排行榜上已经上升至第二名,而DeepSeek上一次更新的V3新模型,已经下滑至第7名。
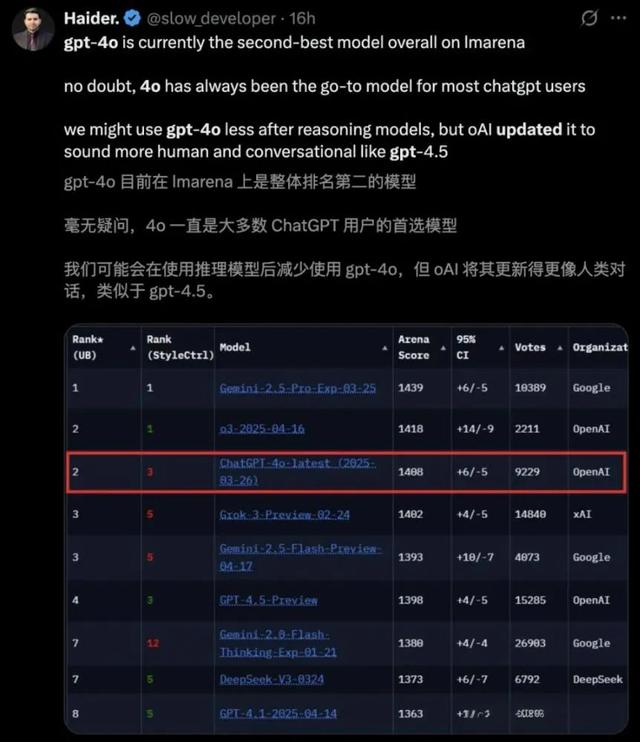
图源:X平台
种种背景的加持下,许多从业者的目光已经不自觉地聚焦在了一个人身上——梁文锋。
作为DeepSeek的创始人,梁文锋在过去的一年中凭借多款模型在全球AI市场中一鸣惊人。然而,随着国内外科技巨头的相继发力,圈内外都在期待梁文锋的下一次出手,期待DeepSeek又将会带来一个怎样“惊天动地”的更新。
从目前的消息来看,梁文锋应该不会让大家失望。

“旧世界分崩离析,新时代正在光速到来”
在AI领域,梁文锋的名字已经成为了一个传奇。
2025年开年,DeepSeek“燃爆”了整个AI圈,其发布的R1模型凭借超低的训练成本和卓越的性能,迅速在全球范围内引起了轰动。
而迄今为止,距离R1模型正式发布已经过去了整整99天,马上就要超百日。这99天,对于DeepSeek来说,是辉煌的起点,也是新的挑战的预热。

图源:中国企业家杂志
2025年1月20日,DeepSeek R1大模型正式发布。而在R1发布之前,DeepSeek团队已经经历了无数次的实验和优化。梁文锋和他的团队深知,要在这个竞争激烈的AI市场中脱颖而出,必须要有独特的优势和创新的技术。
在招人过程中,梁文锋的团队展现了极高的标准和独特的理念。梁文锋对人才没有标签,不论学历背景,不论过往业绩,他只看这个人的个人能力和个人素质。
这种人才观,让DeepSeek的团队成员不仅具备强大的技术能力,更有着对AI的热情和创新精神。
梁文锋曾经说过:“我们招人的原则是看能力,而不是看经验。如果追求短期目标,找现成有经验的人是对的。但如果看长远,经验就没那么重要,基础能力、创造性与热爱等更重要。”
此外,梁文锋对AI和公司的思考,也贯穿了整个R1模型的研发过程。
他认为,语言大模型是通往通用人工智能(AGI)的关键路径。因此,DeepSeek专注于基础研究,而不是急于开展应用开发。
梁文锋坚信,通过不断优化和创新,语言大模型可以逐步实现类人的人工智能。这或许也是DeepSeek如今仍在语言类大模型这条路上走到黑的原因。
但无论怎样,随着时间的推移,距离DeepSeek上一次推理模型的更新时间越来越长,外界对R2模型的期待也越来越高。

图源:微信
此前,DeepSeek曾表示R2模型会在今年年内推出,但否认了前段时间宣称5月甚至4月底会上线的传言。尽管如此,外界对R2的期待并未减少。
许多业内人士认为,R2模型将是DeepSeek的又一力作,有望在性能和功能上实现更大的突破。
据了解,DeepSeek公司目前对外界的各种传言采取不予理睬的态度,更多的是专注于自己的研究当中。梁文锋和他的团队深知,只有通过不断的技术创新和优化,才能在激烈的市场竞争中保持领先地位。
在DeepSeek的崛起过程中,OpenAI一直是其主要竞争对手之一。
然而,国外多家媒体近期却纷纷表示,OpenAI给梁文锋的压力还不够,所以梁文锋才能一直高枕无忧地做自己的事,而不用考虑过多的去对外宣传自己的新模型。
他们认为,OpenAI在面对DeepSeek的快速崛起时,似乎显得有些力不从心,这种感觉美国的AI公司此前几乎从未有过。
不过,OpenAI并未如他们口中所说的那么不堪,可能正应了那句话“瞧不起的往往是自家人”。
实际上,OpenAI近期只是换了打法,更专注于DeepSeek从未涉及的文生图领域。
目前,OpenAI的GPT-4模型在文生图领域可谓是一马当先,其能力也得到了国外众多用户的验证,并且还能驾驭格式各样的风格。

图源:ChatGPT生成图片
随着ChatGPT带来更多的震撼,美国硅谷已经出现一些“文生图和文生视频领域将是未来AI发展的新方向”类似的声音。
因此,外界同样在期望DeepSeek文生图、文生视频大模型的出现。但这个愿望可能不太容易被实现。
梁文锋曾经表示:“我们不会过早设计基于模型的一些应用,会专注在大模型上。从长期看,大模型应用门槛会越来越低,初创公司在未来20年任何时候下场,也都有机会。”
如今,摆在梁文锋面前的现实是,美国政府正在限制英伟达H20芯片等高端芯片向中国出口,而这正是绝大部分AI公司发展的“地基”。
此外,伴随着关税政策不断变化,贸易全球化的大势正在遭受美国单方面的削弱,这也很可能增加DeepSeek团队的研发成本。
因此,在重重压力的考验下,聚光灯下的梁文锋能否带领团队冲破枷锁,让中国AI再次对世界发出震耳欲聋的咆哮,成为了国内外不少人心中的挂念。
作者 | 刘峰



评论列表