第一资本(Capital One)是美国第三大发卡银行。1994年成立的他们,期盼自己成为一家科技公司,在2012年启动数字转型,隔年拥抱敏捷开发、2014年推动IT现代化、2015年投身开源社交媒体、2016年开始上云,直到2020年关闭最后一个本地数据中心,成为美国金融业全面上云的先行者。
上云后的他们,如何确保系统韧性?如何保证每天70亿笔的刷卡交易,都能在毫秒内完成欺诈侦测、确认余额并成功处理?
用公有云可用区域强化可用性
第一资本信用卡架构副总Kathleen deValk在2023年一场会议中,披露自家的网站可靠性工程(SRE)做法。首先,在人力安排上,第一资本没有设立一个专门的SRE团队来维护系统韧性,而是将SRE人力分散在各业务部门一起工作,比如信用卡部,根据事件经验,改善韧性架构。
第一资本上云采取了不同的技术架构,最基础的是公有云企业AWS标准多可用区域(AZ)架构。这个AZ是指实体地理区域中,相互隔离但以低延迟网络连接的数据中心。由于互相隔离,就算单一AZ故障,也不会影响其他AZ,所以企业常在多个AZ中部署应用程序,来提高可用性,或应对突然暴增的流量。这也是第一资本采用的原因。
他们的多区域基础架构中,还分为运算层、数据沟通层和永久数据层等3层,每层有各自的服务。比如运算层有Lambda、ECS、Fargate等AWS服务,来执行函数和容器。数据沟通层有Amazon SQS、AWS AppSync等服务,来调度数据处理工作。永久数据层有RDS、DynamoDB、S3等AWS数据库和存储服务,来处理数据湖、机器学习(ML)和分析等任务。为确保服务不中断,第一资本将这3层服务,部署在3个AZ,每个AZ都能执行这3层服务,以便一个故障时,其他AZ可以接手支持。
韧性做法1:多区域故障转移架构
有了这个基础,第一资本进一步设置更细致的韧性机制,其一是多区域故障转移架构。当负载均衡器侦测到系统故障,能自动将流量转移到另一个AZ,甚至自动触发后续功能,例如修复系统、回收执行实例、重新连接数据库等等。
自建监控仪表板是这项韧性机制的关键,可根据每支应用程序定制的健康指标,来检测系统健康状况。这些健康指标,有其相对应的阈值。在系统设计阶段,第一资本会通过负载测试、性能测试、扩展测试和边界测试,来找出可参考的阈值设计。
“但不能止步于此!”Kathleen deValk强调,讲求韧性的网站可靠性工程是一个持续学习的过程,所以,第一资本得随着时间演进不断优化、微调阈值,才能更快侦测到问题、自动修复。
韧性做法2:AA多区域架构
另一个做法是采用AA多区域架构。有别于多区域故障转移架构的AP架构、故障切换可能需要几秒到几分钟,AA架构可以近乎即时切换,也更容易水平扩展。也因此,第一资本最常在讲求时效的业务场景中,采用AA多区域架构的做法,比如信用卡交易。
在他们的AA架构中,依然用Lambda、ECS和Fargate等服务来执行容器、以S3和DynamoDB处理数据存储和分析任务。由于信用卡交易涉及多个系统,每个系统的数据复制时间若为1秒,累积起来就很耗时。于是,他们采用DynamoDB的全局表功能,来尽可能缩短时间。
他们还有一项特别的做法:采取120%的过度配置。为什么要用更高的成本,使用过多的资源,而不是刚刚好就好?
因为,不论何时发生故障,比如节点故障、EC2执行实例故障或AZ脱机,他们都可以通过过度配置,来重新分配工作负载,并分担工作量,避免影响到顾客服务。“但要记得一件事,在AA架构中过度配置,云计算成本容易暴增,”Kathleen deValk提醒,何时使用过度配置,还得视第一线业务需求而定。
韧性做法3:区域工作负载分配
不只如此,第一资本还有个区域混合方法,来兼顾韧性和处理速度。试想,人们刷卡的当下,银行接到交易通知,得要先侦测这笔交易是否为欺诈,通过后再确认账户余额是否足够。要是不够,系统可能临时决定给予额外额度、完成交易。这么多个事件,都要在几百毫秒内进行。
因此,系统间的通信速度得快,更需要一致。第一资本发现,要做到这一点,就不能用不同区域的资源,来跳跃处理API调用链,因为他们曾测试发现,光用2个区域处理2次API调用,就耗费200毫秒!要是一个调用链有10个步骤,累加起来就是很可观的延迟。
所以,他们规划用2种技术来分配工作负载,一是采用AWS基于延迟的分配方法,来将负载自动分配到最有效率的区域,另一是在UI触发API调用链后,改由该地的区域来执行,避免中间切换不同区域处理所衍生的延迟。
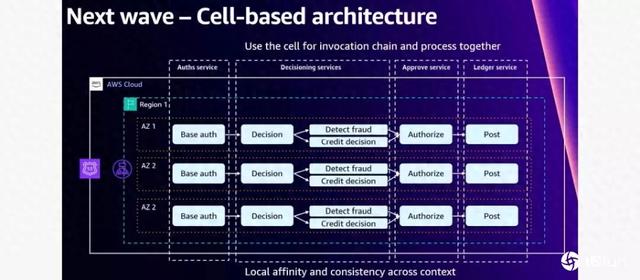
为做到这一点,第一资本还打造单元架构(Cell-based Architecture),将原本一支支微服务,按端到端流程隔离成一个单元,比如将信用卡验证微服务、欺诈判断微服务、授权微服务和处理微服务隔离成一个单元,并限定在同一个AZ执行。只有在故障发生时,才转移到另一个AZ,来缩短处理延迟。
真实事件的反思:监控系统也要高可用
不过,2021年,第一资本遇到一场让全公司鸡飞狗跳的事件:云计算DNS网络服务AWS Route 53故障了。第一资本因此发生许多系统错误,经过与AWS重重沟通和根本原因分析,从中总结许多宝贵教训。
第一是监控,“如果看不到正在发生的事,就像盲人一样,无法做任何反应。”Kathleen deValk点出,他们发现,自家一些监控系统并没有在多区域执行,因此受Route 53故障影响,这些监控系统故障,看不到系统即时状况,就算出问题,也难以解决。
第二是无法访问控制台,导致备用的日志起不了作用,排除故障也更困难。
第一资本根据这2个教训,着手改善原本架构。首先是构建关注机制,在日志系统中,当用户功能被调用时,插入一个关联ID,让这个ID随着功能处理流程传递下去。如此一来,技术团队就能在故障发生时,找到故障所在之处,还能能更好地分析故障原因、设置更合适的重试和退回方案。
再来,他们也采用真实用户监控方法,将用户每个访问系统的动作,都记录在日志。这么做,第一资本可以看到用户与系统互动时,系统的即时状况。综合这些方法,他们可以打造预测性监控仪表板,进一步在日志中寻找事件发生前的预警信号,尽早介入处理。
第一资本通过这些新方法,成功揪出潜在事件,比如侦测到一款应用程序的连接池不断扩大,于是他们检查基础设施、找出问题根源并解决。
这种从事件中吸取教训、进而回头改善IT架构设计,正是第一资本追求的“架构+SRE”最佳实践。