[LG]《RL Fine-Tuning Heals OOD Forgetting in SFT》H Jin, S Luan, S Lyu, G Rabusseau... [Polytechnique Montreal & University of Montreal & McGill University] (2025)
两阶段微调揭示:监督微调(SFT)并非单纯记忆,强化学习(RL)不是简单泛化,而是修复SFT中的OOD遗忘。
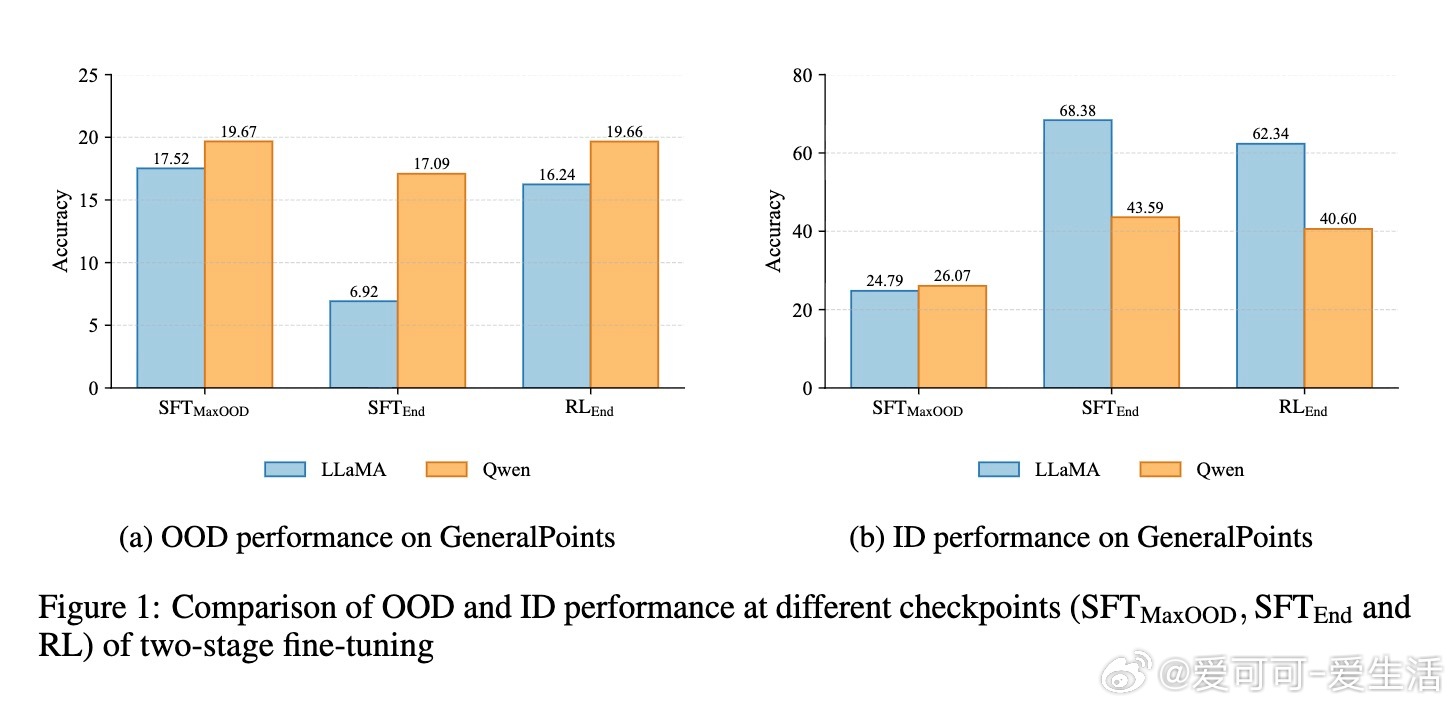
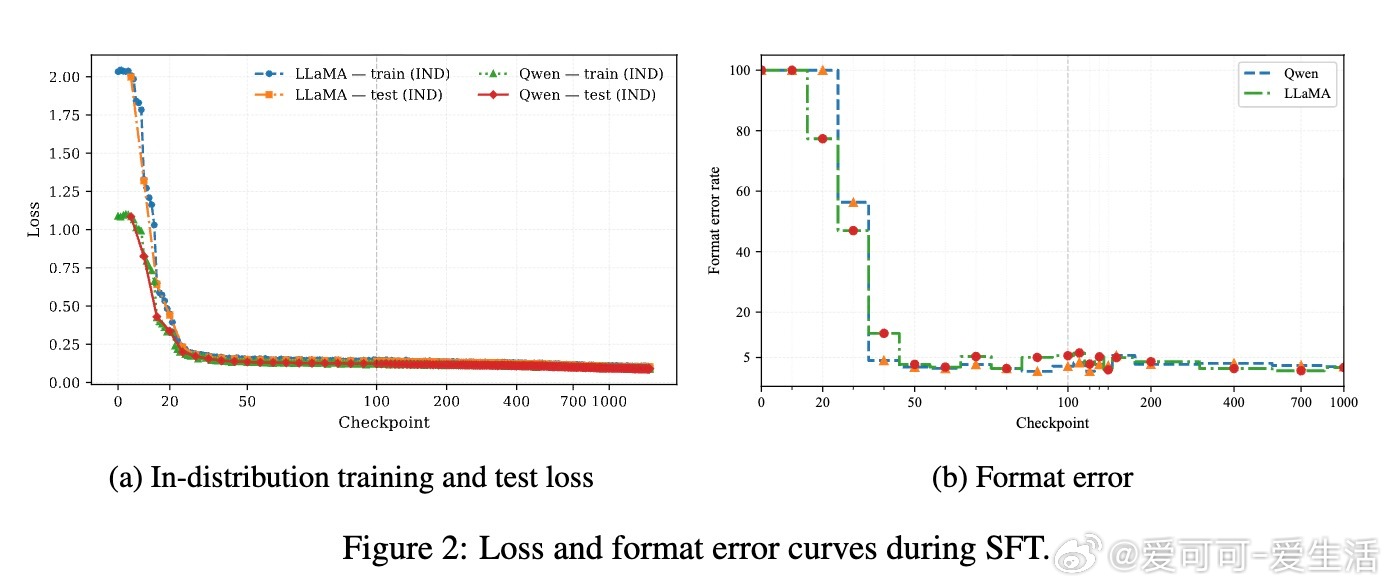
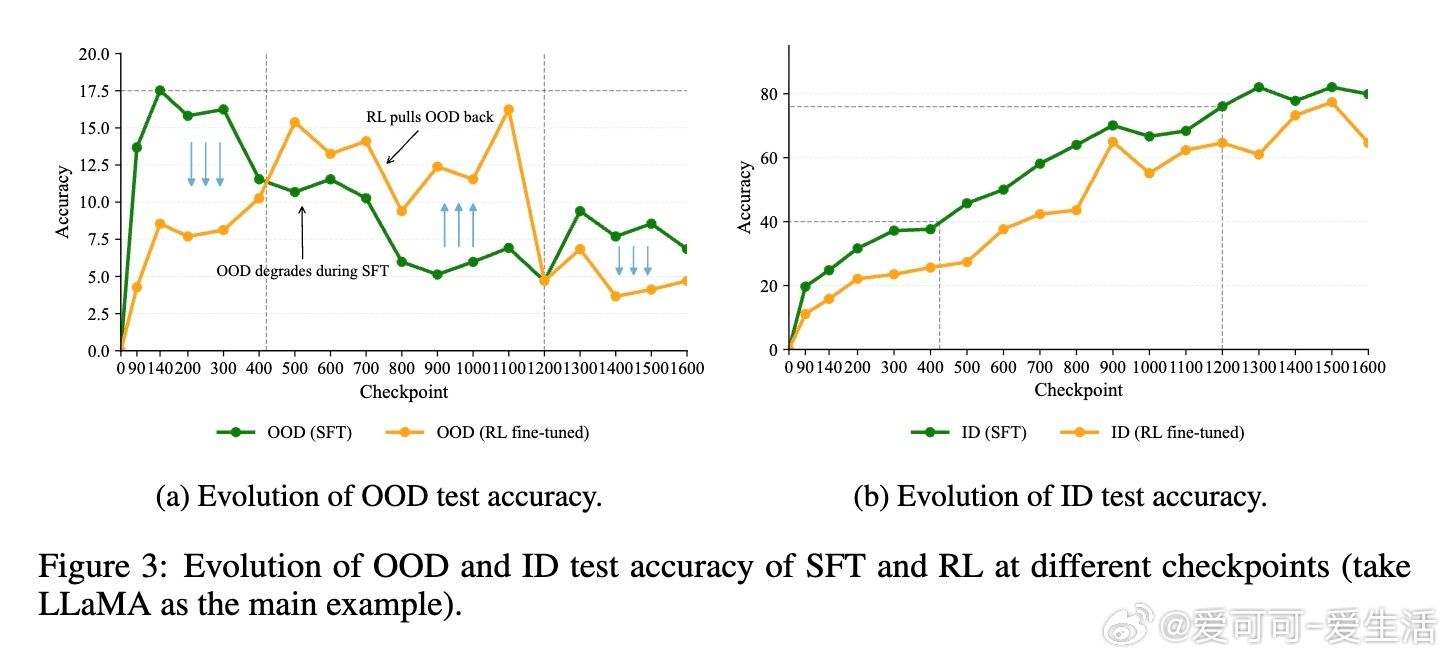
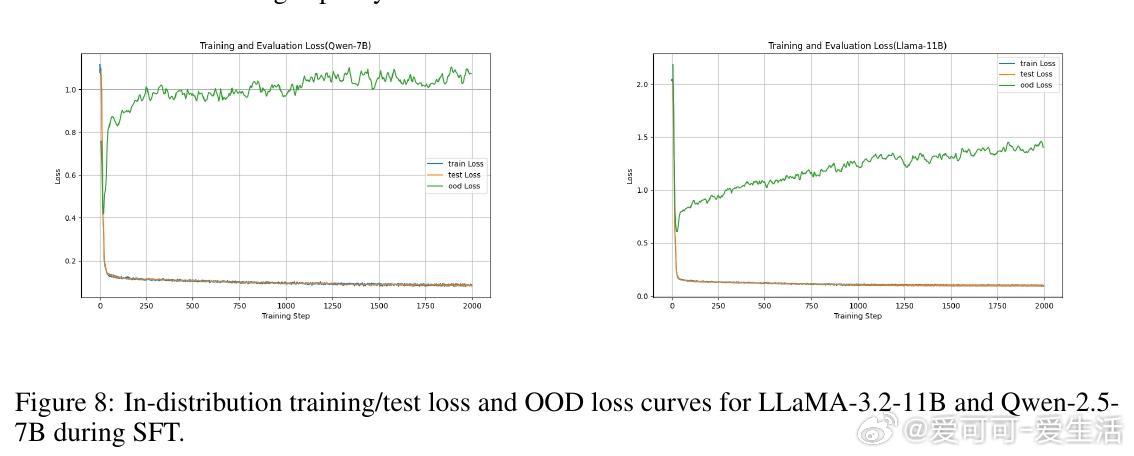
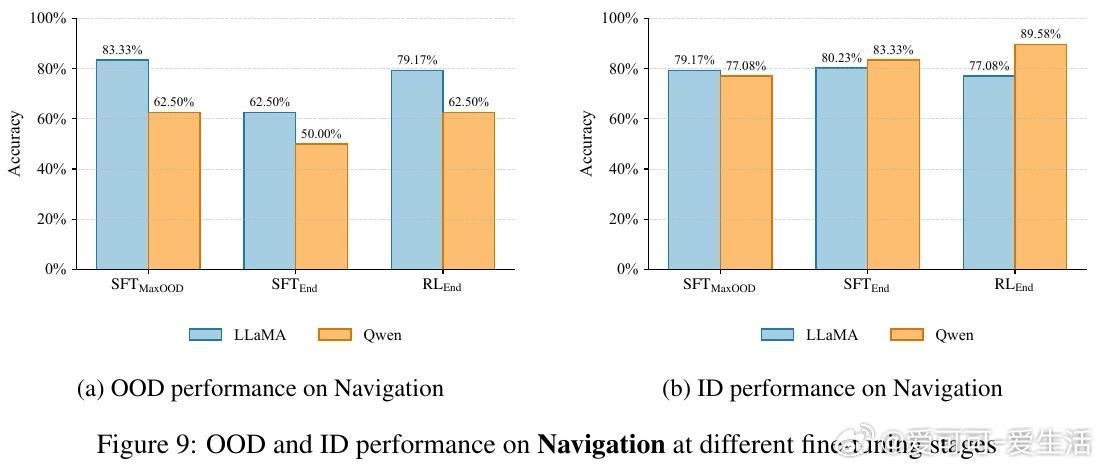
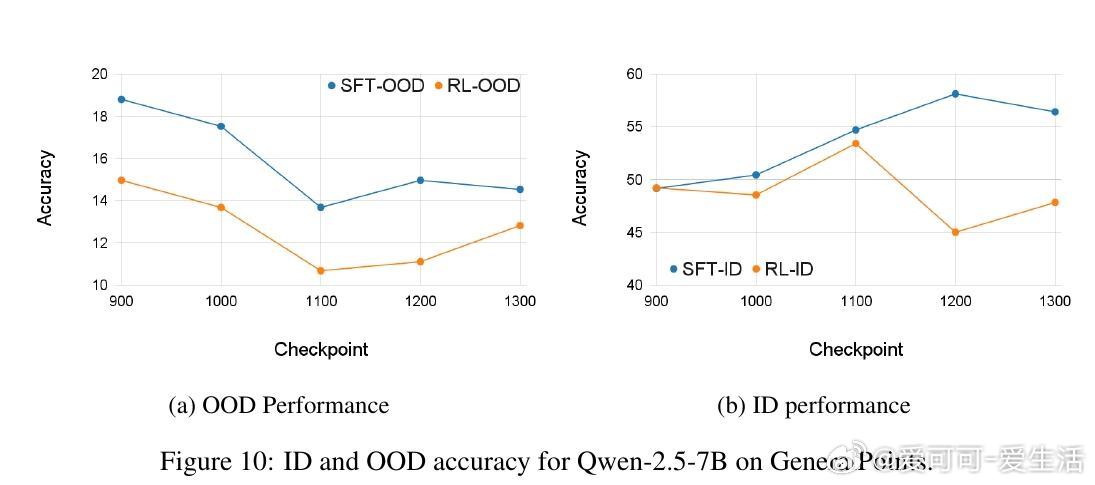
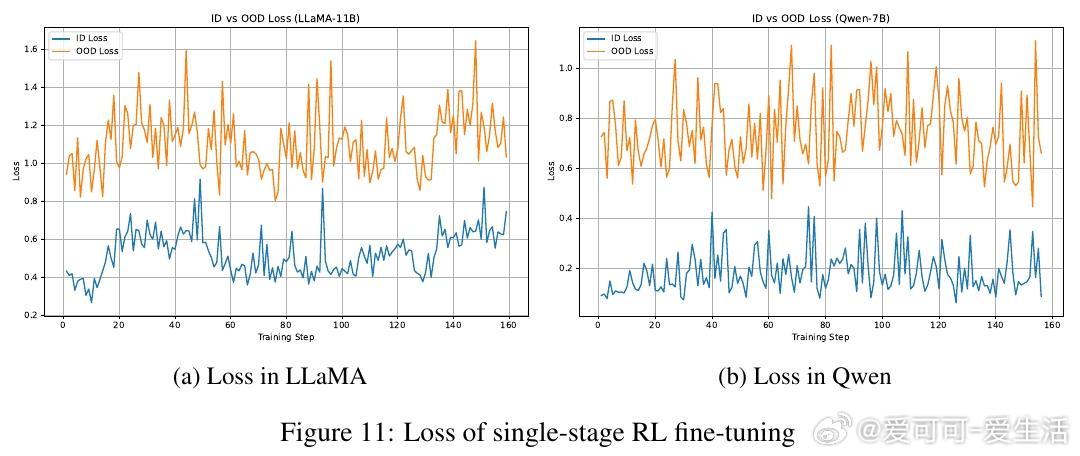
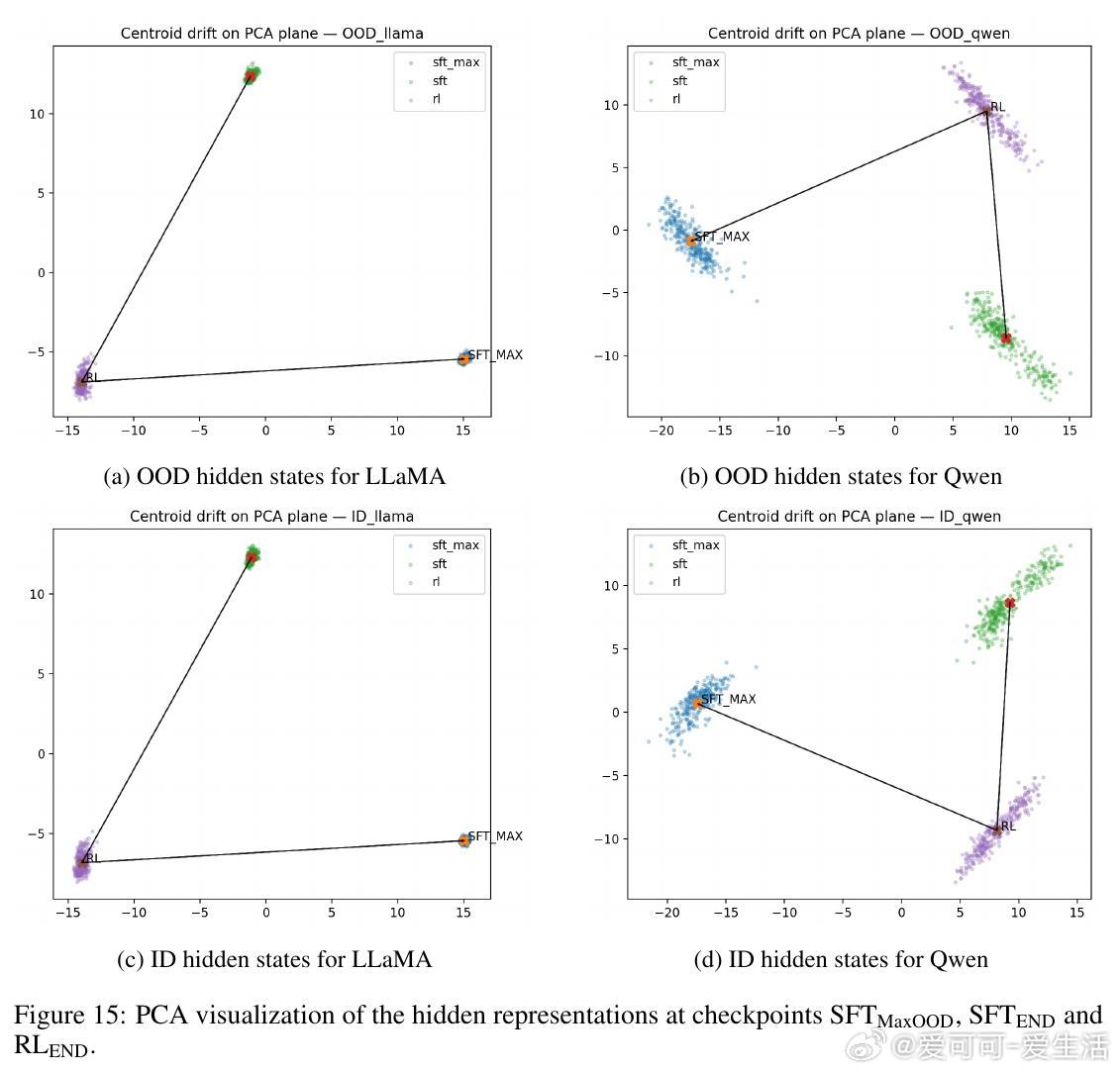
• 通过对LLaMA-3.2-11B与Qwen-2.5-7B模型在GeneralPoints算术推理任务中的多阶段评估,发现SFT早期即达到OOD性能峰值(SFT_MaxOOD),随后出现“OOD遗忘”——模型虽在ID任务上持续提升,但OOD表现下降,传统损失曲线难以捕捉此现象。
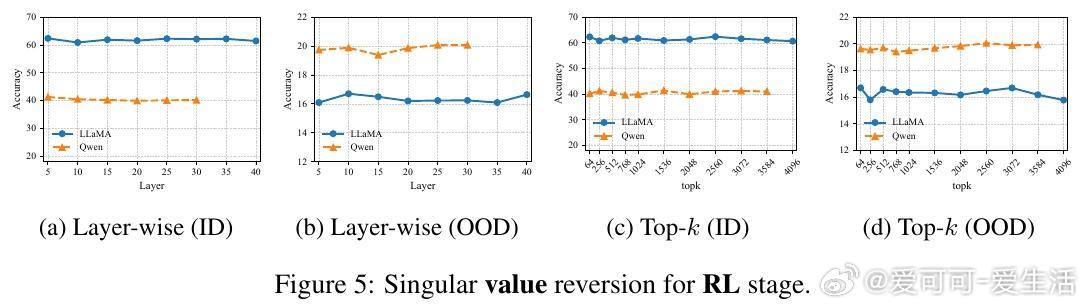
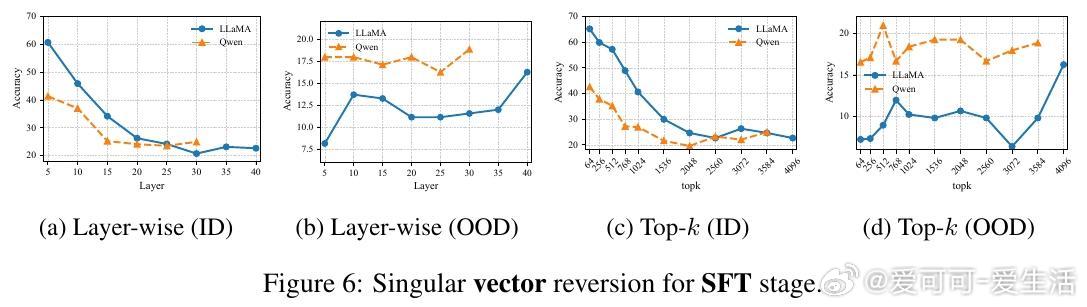
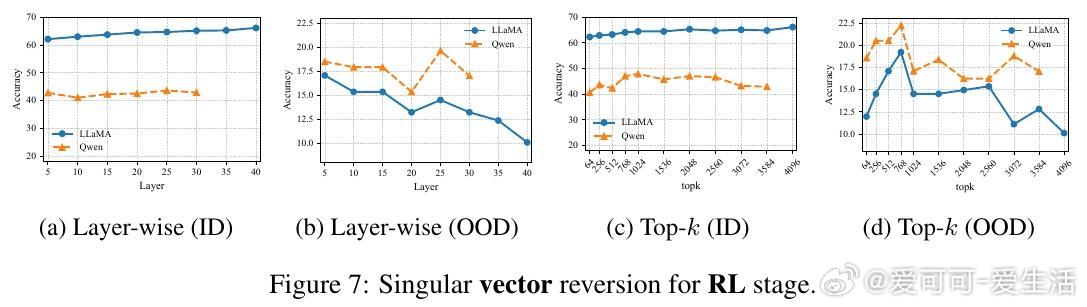
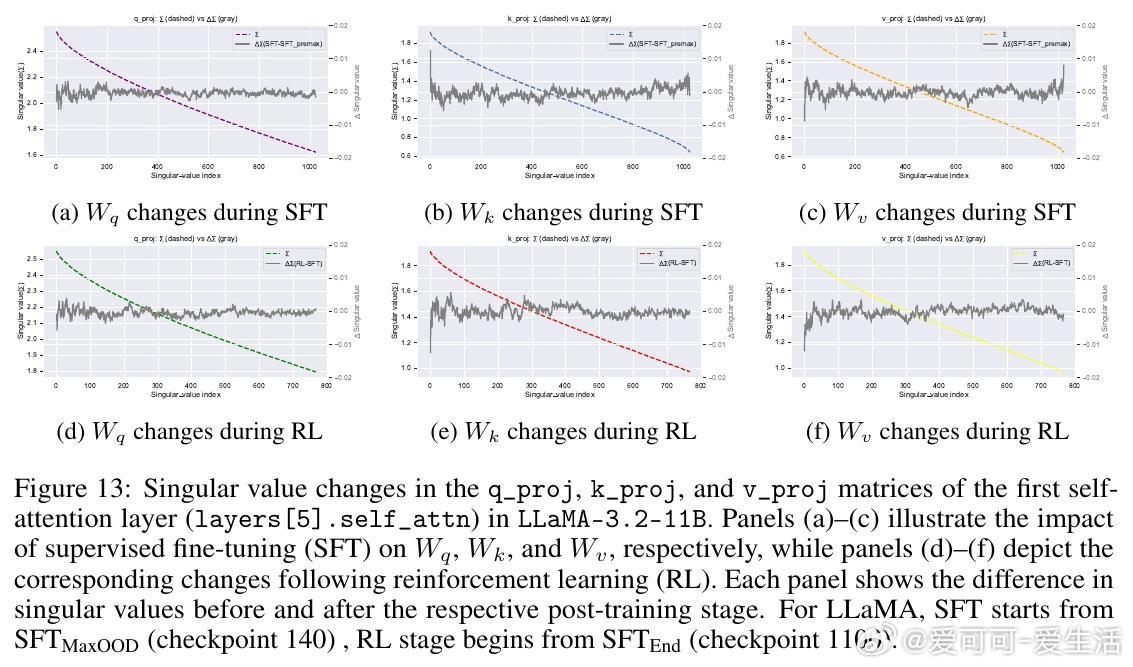
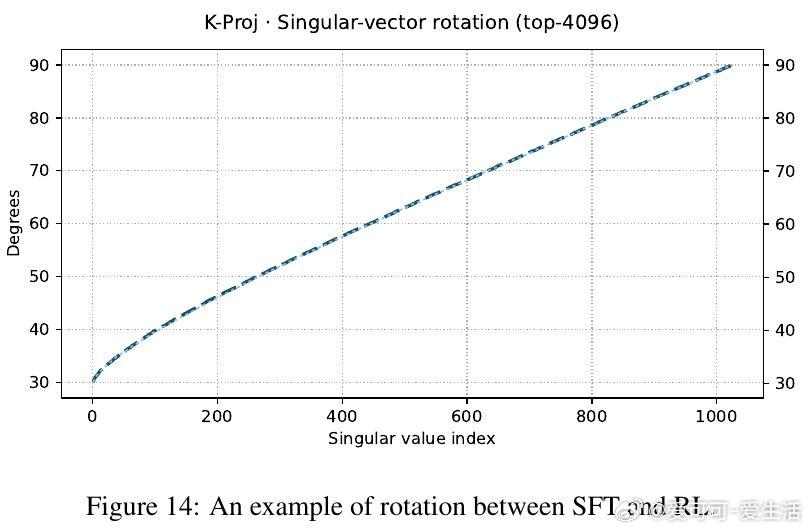
• RL微调并不创造全新OOD能力,而是在一定SFT训练区间内(如LLaMA在420至1200检查点间)软性旋转奇异向量,恢复SFT遗失的OOD推理能力,类似于自动正则化,避免了手动选点的繁琐。
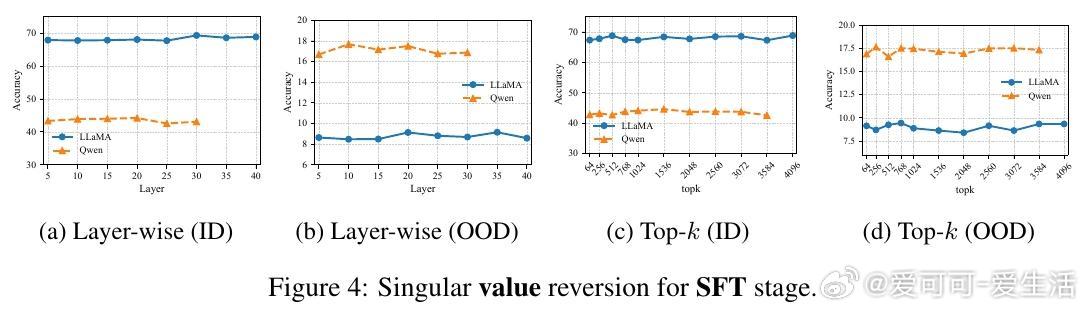
• 奇异值(singular values)在微调过程中几乎稳定,关键影响因素是奇异向量的旋转,即模型参数空间的方向调整。SFT执行“硬对齐”,快速且贪婪地适应任务,导致快速遗忘;RL则进行条件性“软对齐”,恢复鲁棒性同时兼顾任务学习。
• 层级与top-k奇异向量分析显示,SFT和RL对不同层和向量子空间的影响存在差异,RL的影响更均匀,且Qwen模型表现更为稳健。
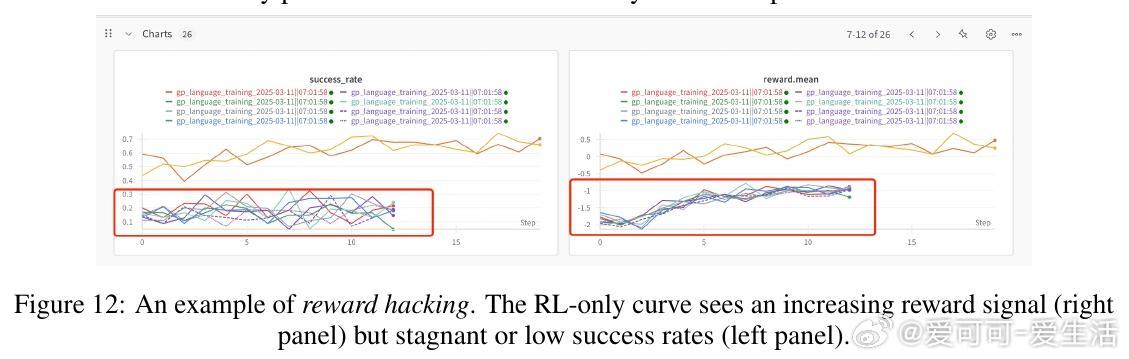
• RL单独启动训练效果不佳,需依赖SFT初始化以避免奖励信号稀疏导致训练崩溃。
心得:
1. 微调策略需关注模型泛化能力的“遗忘-恢复”动态,而非单纯追求训练损失最小化。
2. 模型参数的“旋转”比“缩放”更能反映能力演变,启示我们设计更有效的微调正则项。
3. RL在大模型微调中作用更像是“补偿”和“稳定器”,非万能提升手段,需合理设定SFT终止点和RL启动时机。
详见🔗arxiv.org/abs/2509.12235
代码开源👉github.com/xiaodanguoguo/RL_Heals_SFT
大模型微调强化学习奇异值分解OOD泛化LLM研究