8图讲解TPU原理TPU硬件架构详解
博主Henry Ko用一组生动的图片,详解了TPU的主要工作原理。
TPU(Tensor Processing Unit)是谷歌为满足AI应用和深度学习设计的处理器,其架构设计独具特色,能提供极高的计算吞吐量和能效。
接下来,我们将通过一系列图示,深入了解TPU的硬件架构和工作原理。
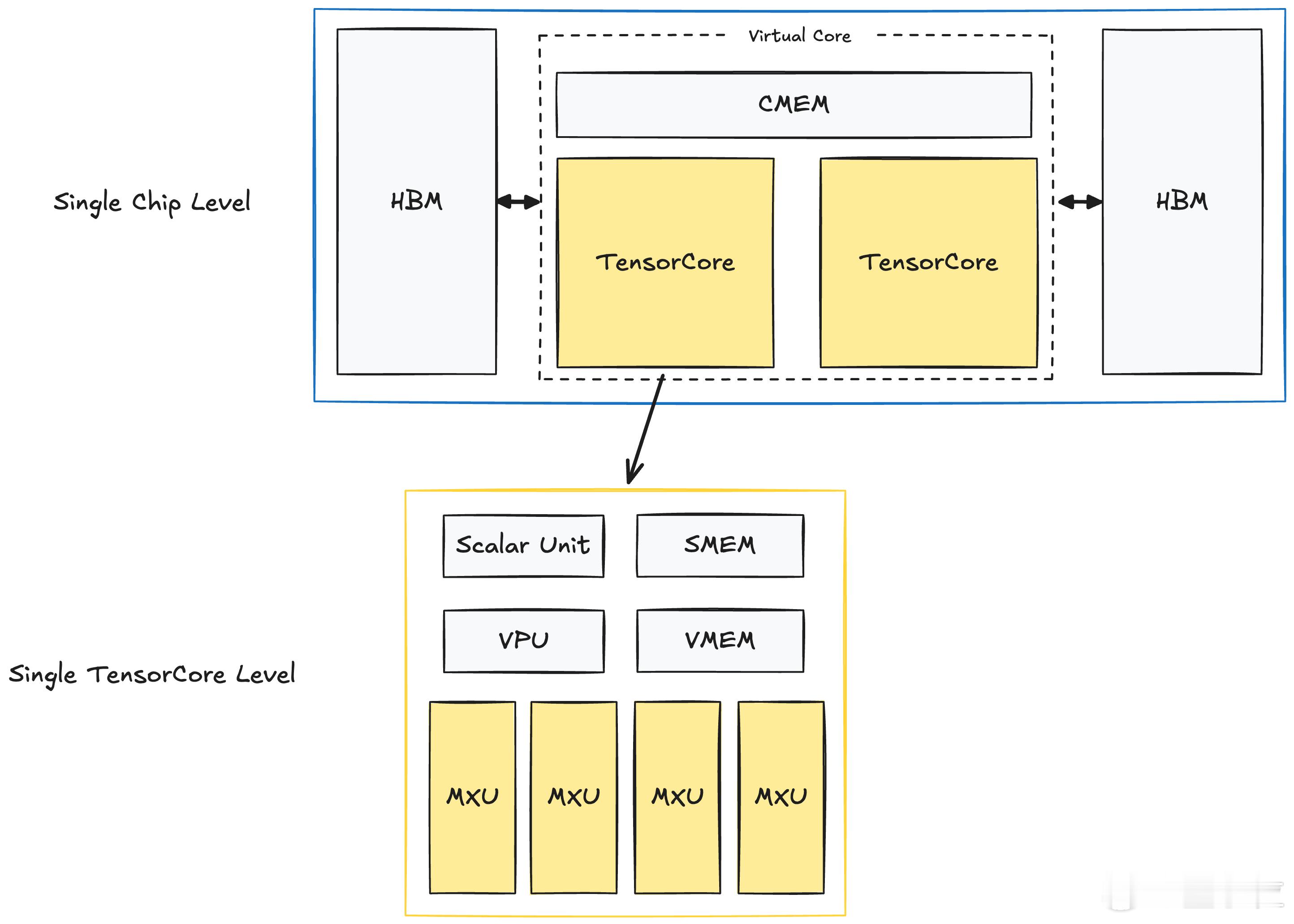
【图1】:单个TPU芯片架构
这张图展示了TPUv4芯片的架构布局。在每个TPU芯片中,包含两个TensorCore计算单元。每个TensorCore负责大规模的矩阵运算(MatMul),这也是TPU的核心功能。而每个TensorCore配备了多个计算单元和内存单元,包括矩阵乘法单元(MXU)、向量处理单元(VPU)、向量内存(VMEM)以及标量内存(SMEM)。这些内存单元配合高带宽内存(HBM)和共享内存(CMEM)工作,确保数据传输的高效和低延迟。这种设计使得TPU能够快速处理深度学习中的矩阵运算。
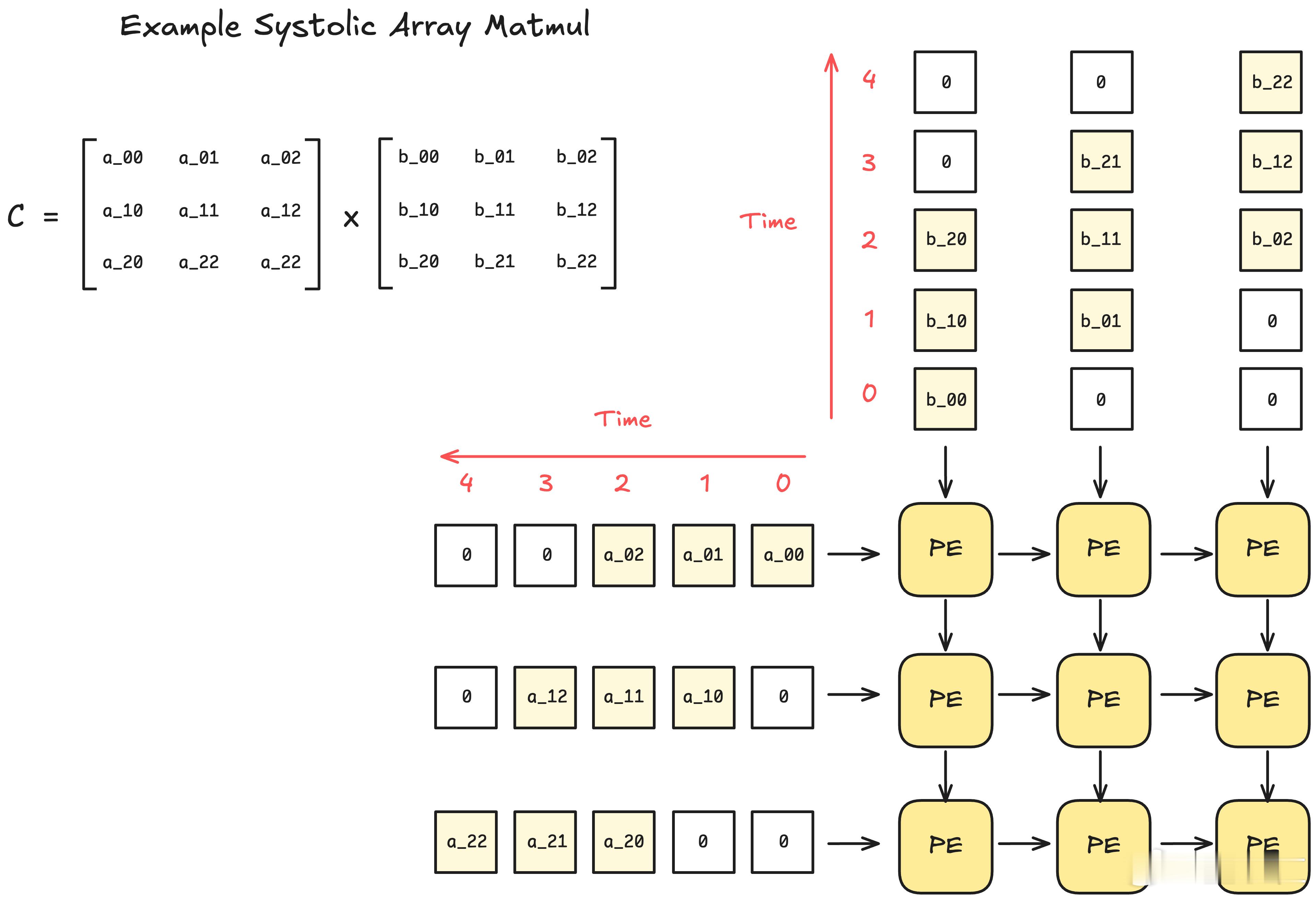
【图2】:系统阵列MatMul操作示例
TPU利用Systolic Array(系统阵列)来执行矩阵乘法。每个处理单元(PE)进行一小部分计算,然后将计算结果传递给相邻的处理单元,最终完成整个矩阵的运算。图中的矩阵A和B被拆分成小块,逐步传递给各个PE进行计算。Systolic Array的优势在于,一旦数据进入阵列,后续的计算几乎不需要额外的内存读取,数据流动完全依赖于处理单元之间的相互传递。这样的设计优化了内存访问,并使得大规模矩阵乘法能高效执行。
【图3】:TPU数据流和内存操作
这张图展示了TPU内部的数据流动和内存操作。TPU使用了多个内存单元来处理数据。
- HBM(高带宽内存)位于最底层,存储大规模数据,并将其传输到其他内存单元进行处理。
- VMEM(向量内存)用于存储并处理来自HBM的数据,数据在此缓冲并被进一步传送到计算单元。
- VREGs(向量寄存器)用于存储处理中的数据块,并提供给计算单元(如MXU和Vector)进行运算。
- SMEM(标量内存)用于存储标量数据,支持更基础的计算任务。
这些内存单元的协作,确保了TPU能够高效地处理并执行大量计算任务,在大规模矩阵运算(如MatMul)时,数据流动与计算的效率至关重要。
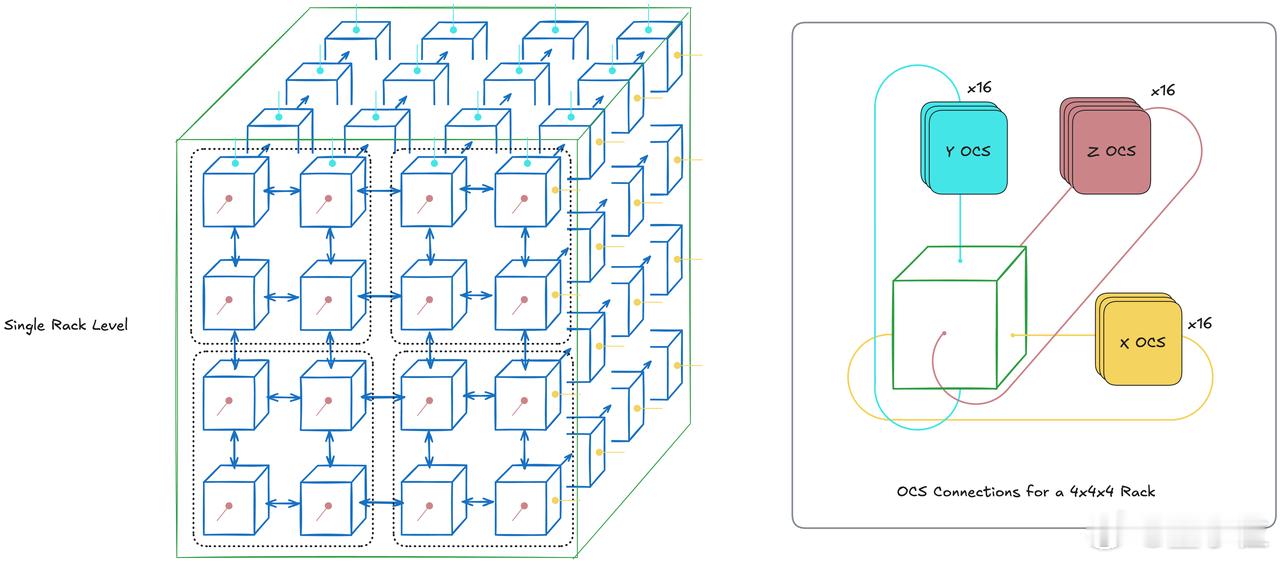
【图4】:TPU机架布局和OCS连接
这张图展示了单个TPU机架的结构以及机架内部的连接方式。一个TPU机架包含多个TPU芯片,这些芯片通过芯片间互联(ICI)和光电交换(OCS)技术互相连接。图左边显示了一个4x4x4的3D网格布局,每个小方块代表一个TPU芯片。芯片通过ICI实现高速的数据传输,并通过OCS技术在机架内外进行优化的通信。
右侧展示了OCS连接的具体细节,其中显示了如何通过OCS在不同维度(X、Y、Z轴)连接多个芯片。每个芯片可以与其它芯片进行数据交换,确保在大规模并行计算时,不同TPU芯片之间能够快速、高效地协同工作。
通过这种3D拓扑和OCS连接,TPU机架能够有效地支撑大规模的并行计算任务,并为更大范围的计算系统扩展打下基础。
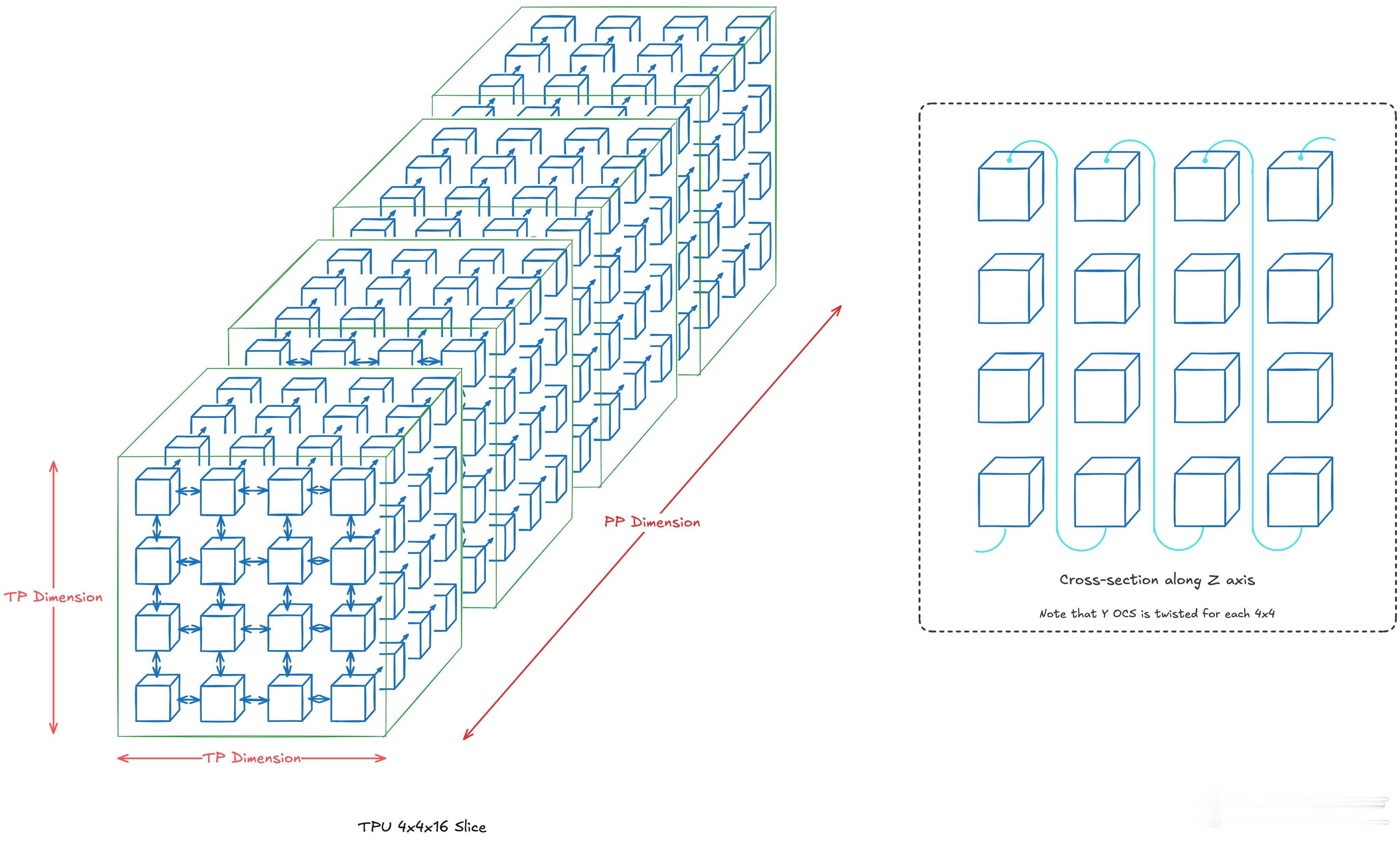
【图5】:TPU机架布局
TPU的可扩展性非常强大,这一点从单个TPU机架的设计中得以体现。每个TPU机架包含64个TPU芯片,通过芯片间互联(ICI)和光电交换(OCS)技术将多个芯片高效连接在一起,形成一个完整的计算单元。图中的TPU机架采用4x4x4的3D拓扑结构,确保芯片之间能够快速进行数据交换和并行计算。这种设计让TPU能够在大规模应用中保持高效的计算和低延迟的通信。
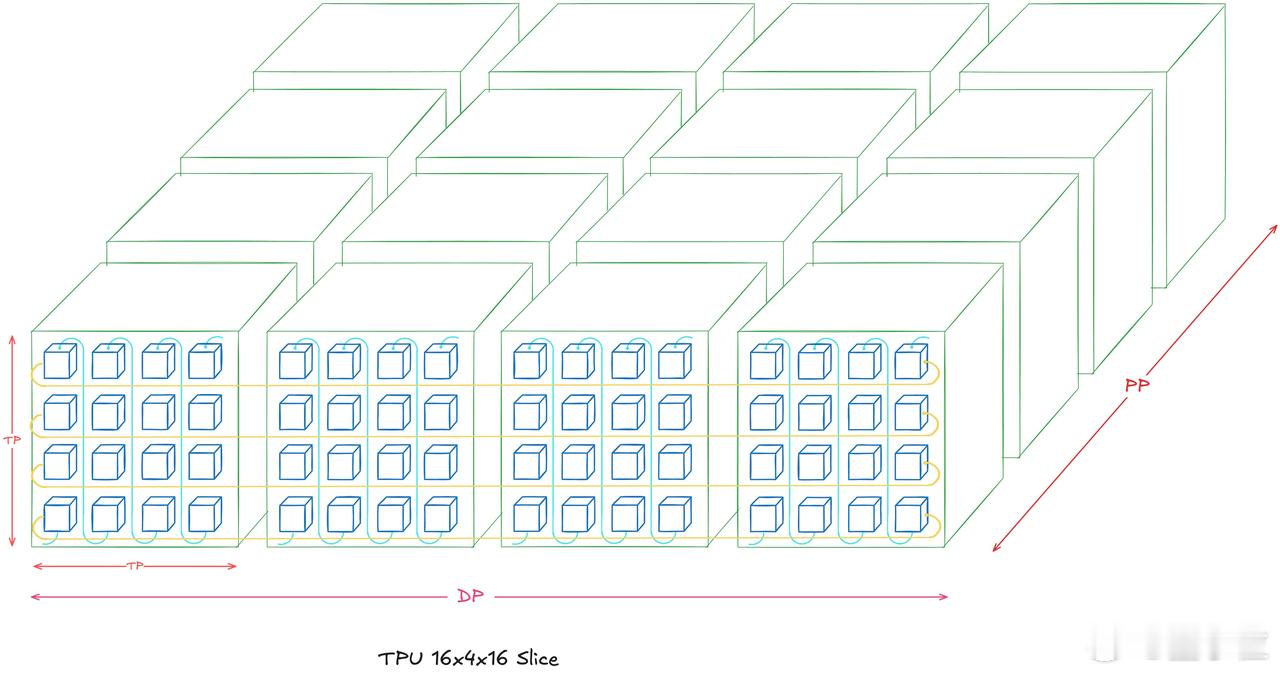
【图6】:TPU超Pod和拓扑连接
当多个TPU机架组合成一个超Pod时,TPU的可扩展性更加明显。一个TPU Pod由64个机架组成,总共支持4096个TPU芯片。通过ICI和OCS,多个Pod之间可以实现高效的数据传输和协同工作。图中展示了如何通过这些高带宽的连接技术将多个机架组成一个完整的计算单元,支持大规模并行计算和复杂的AI训练任务。
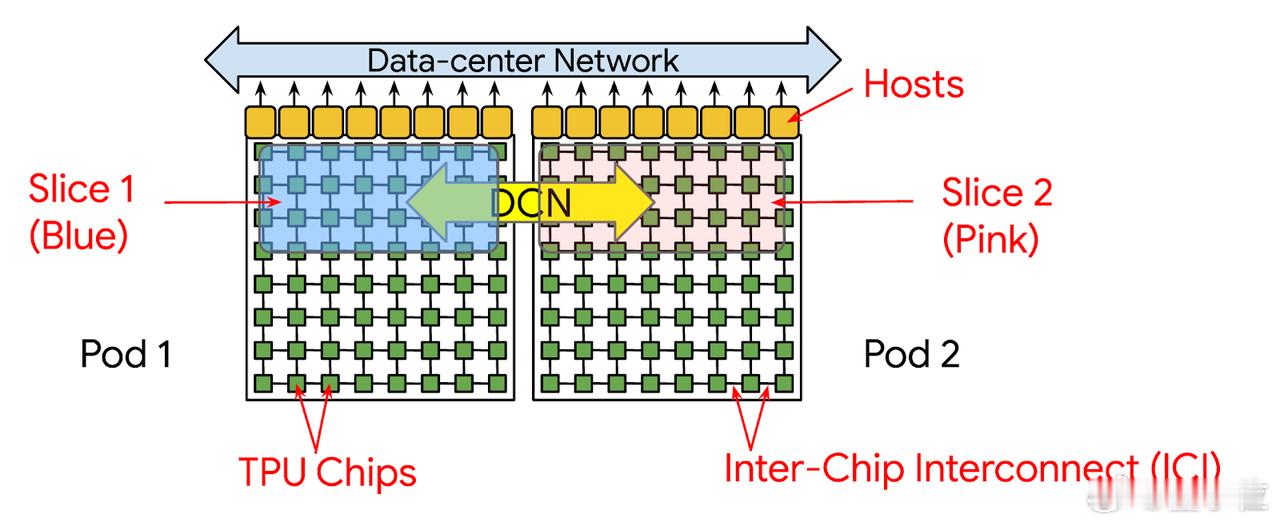
【图7】:TPU Pod和Slice结构
这张图展示了多个TPU Pod和Slice的连接与组织结构。每个TPU Pod由多个TPU芯片组成,其中显示了两个Pod(Pod 1和Pod 2)。每个Pod内的TPU芯片通过芯片间互联(ICI)技术进行高效连接,以实现快速的数据交换和并行计算。
图中用蓝色和粉色标记了两个不同的Slice(Slice 1和Slice 2),它们是从Pod中提取的计算单元,通常用于根据计算需求进行分割和并行化。Slice 1和Slice 2之间通过数据中心网络(DCN)进行连接,确保数据在不同Slice之间高效流动。
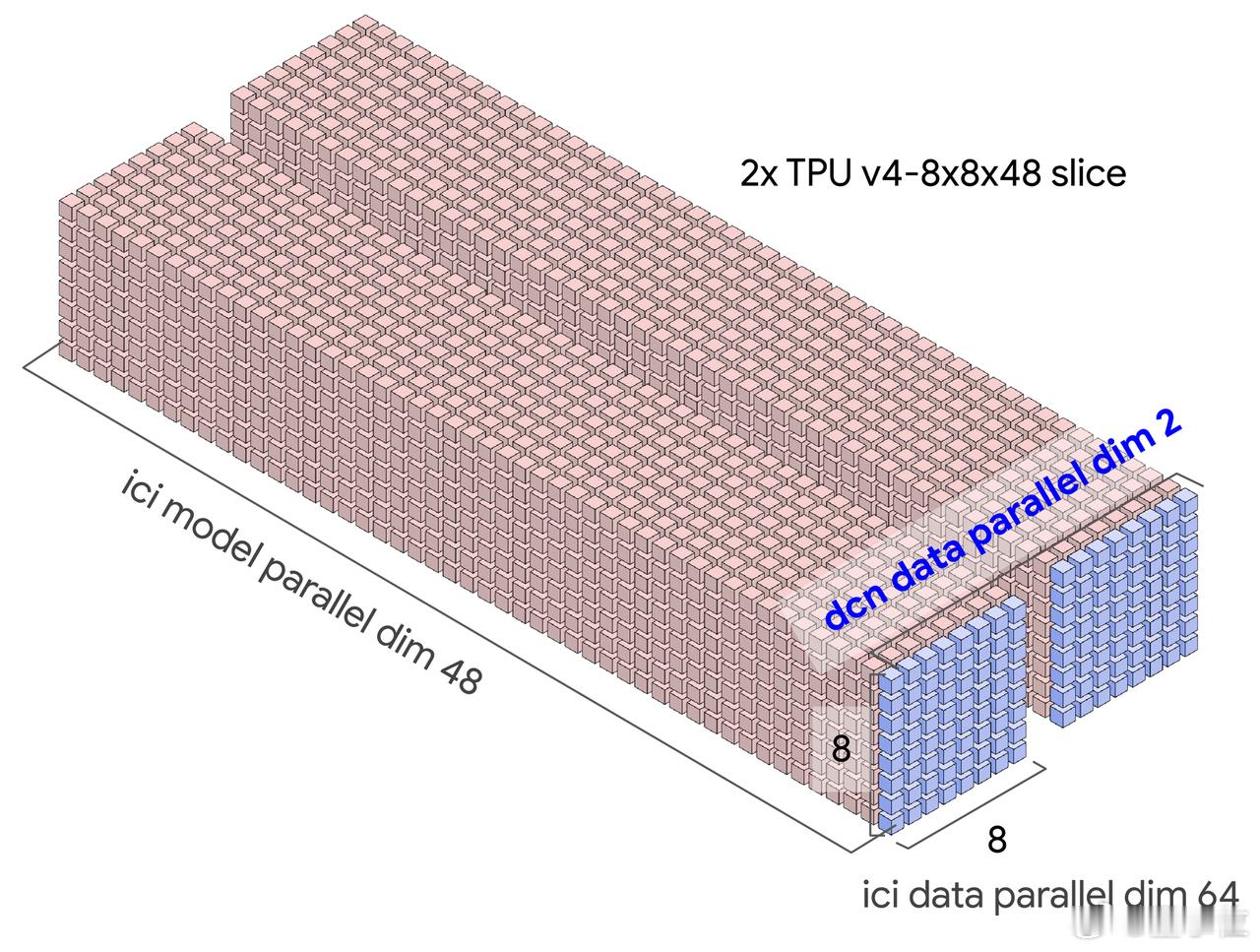
【图8】:TPU v4 8x8x48切片和数据并行拓扑
这张图展示了2个TPU v4 8x8x48切片的结构布局,每个切片由多个TPU单元组成。在这个布局中,TPU芯片被组织成3个主要维度:模型并行维度(model parallel dimension)、数据并行维度(data parallel dimension)和芯片间互联(ICI)维度。
- ICI模型并行维度(model parallel dim 48):这个维度将TPU芯片划分为48个部分,每部分负责计算任务中的不同模型部分,支持模型的并行计算。
- DCN数据并行维度(data parallel dim 64):这个维度展示了如何将数据并行化,TPU芯片通过数据中心网络(DCN)进行连接,每个维度上有64个数据块,共同处理不同的数据部分。
- ICI数据并行维度(data parallel dim 64):这个维度展示了在ICI层面的数据并行性,每个TPU切片的计算和数据传输都可以并行处理。
图中还显示了切片的结构:8x8的维度配置,意味着每个TPU芯片的计算任务和数据分布是均匀的,这样可以在多个TPU芯片之间高效分配计算负载,最大化资源利用。
通过这种多维度并行化的设计,TPU能够处理更大规模的计算任务,并在大规模训练中实现更高的吞吐量和效率。
感兴趣的小伙伴可以阅读原文: