AI玩贪吃蛇学会数学推理不学数学也能懂数学推理
玩会儿贪吃蛇和俄罗斯方块,AI居然就把数学推理给学会了?
传统上,要想让AI学会某个领域的知识,就得给它喂一大堆那个领域的数据。
来自莱斯大学、约翰霍普金斯大学和英伟达的研究人员,提出了一种名为“视觉游戏学习”的后训练范式,让模型在玩游戏的过程中,就掌握了跨领域多模态推理。【图1】
这道理其实不难理解,就像我们人类玩游戏能锻炼反应和思维一样,这些游戏成了AI的“训练营”,让它在玩乐中提升各种能力。
研究团队专门设计了两款游戏环境,用来训练不同类型的思维。他们以Qwen2.5-VL-7B模型为基础进行了训练:【图2】
- 贪吃蛇:模型在10x10的网格里控制两条蛇去抢苹果。
- 旋转游戏:这个灵感来自俄罗斯方块,模型需要从不同角度观察3D物体,并识别它们在旋转90度或180度后的样子。
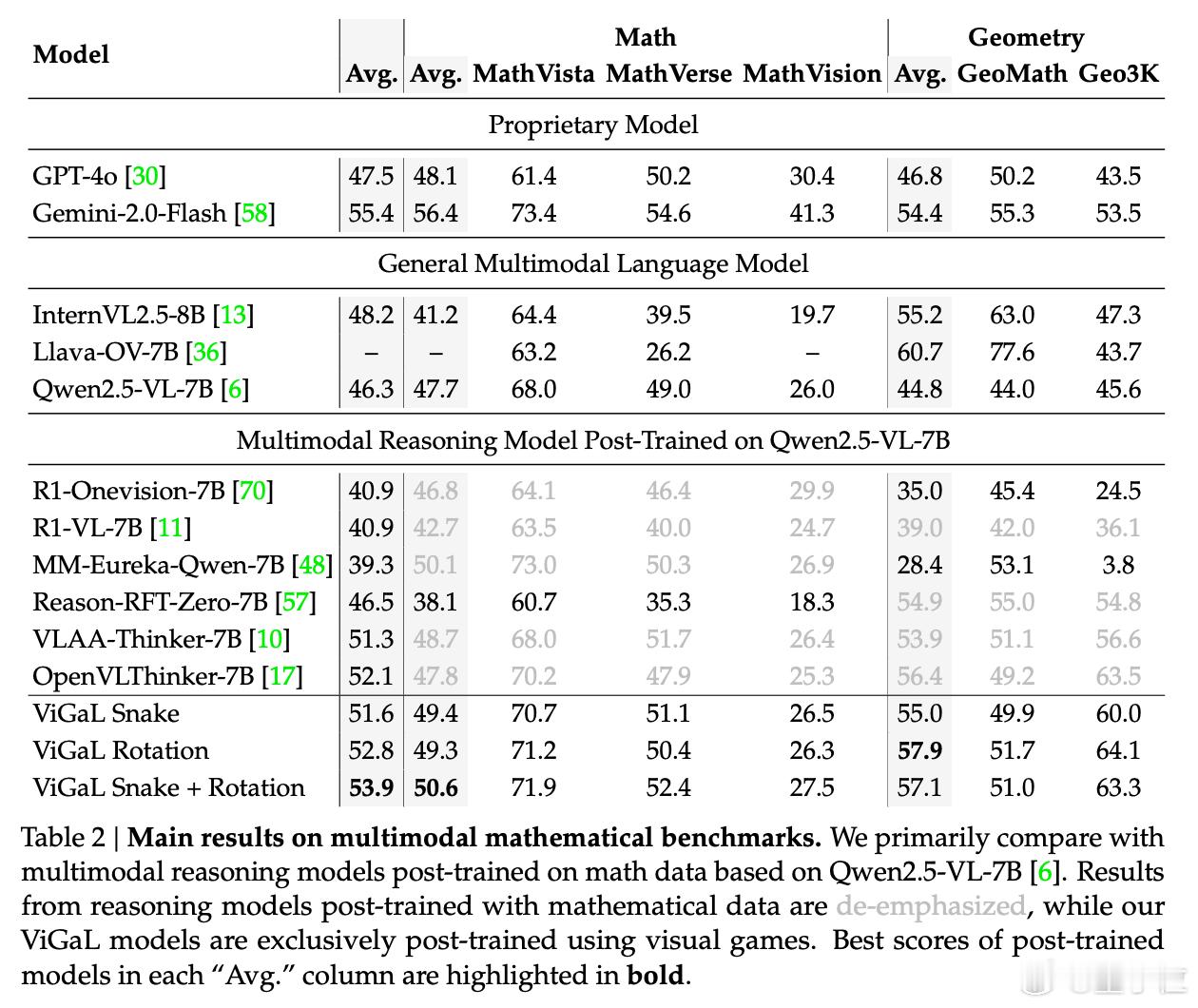
实验结果显示,经过《贪吃蛇》和旋转问题训练后,基础模型以50.6%的准确率略微领先专攻数学数据的MM-Eureka-Qwen-7B模型(50.1%)。【图3】
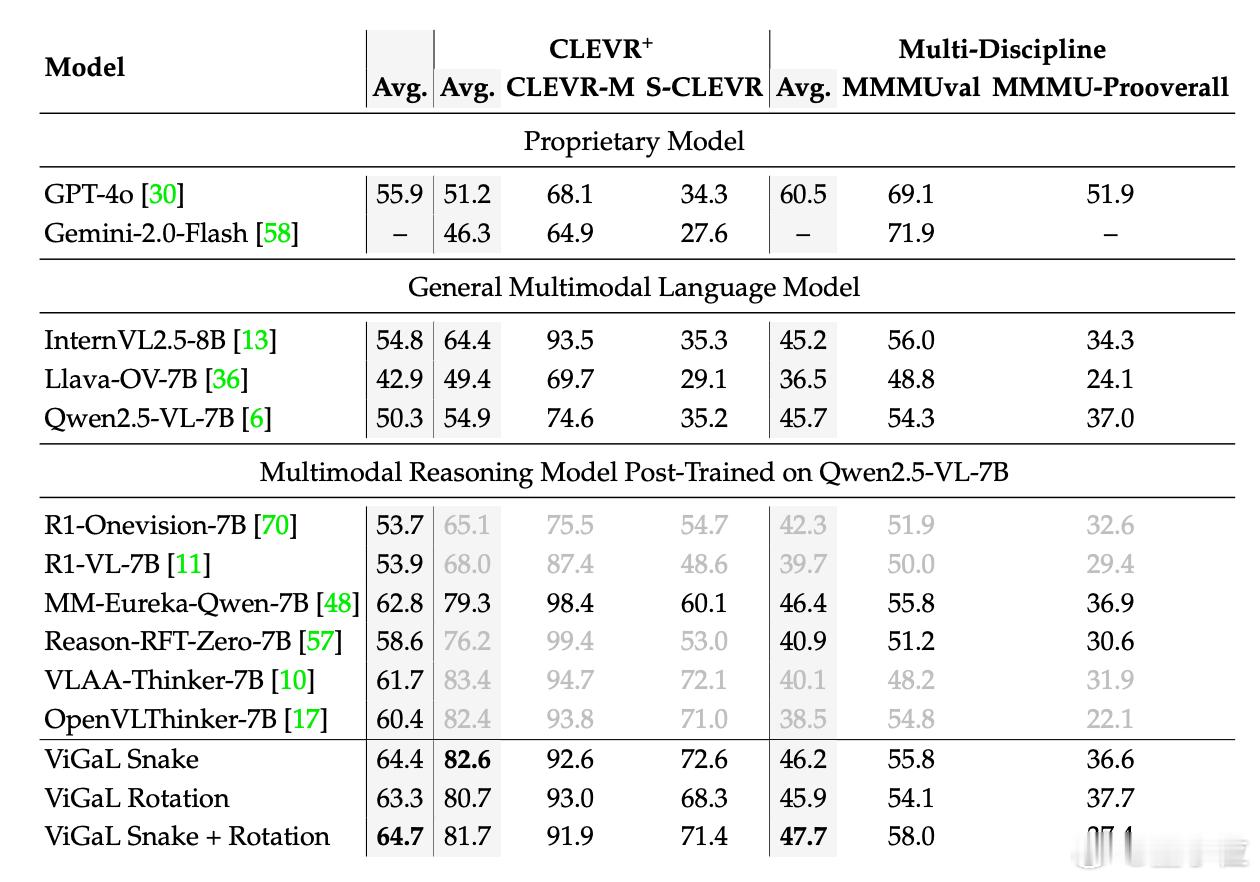
在更难的数学题上,这个小规模再训练模型以64.7%的准确率超越GPT-4o(55.9%)。【图4】
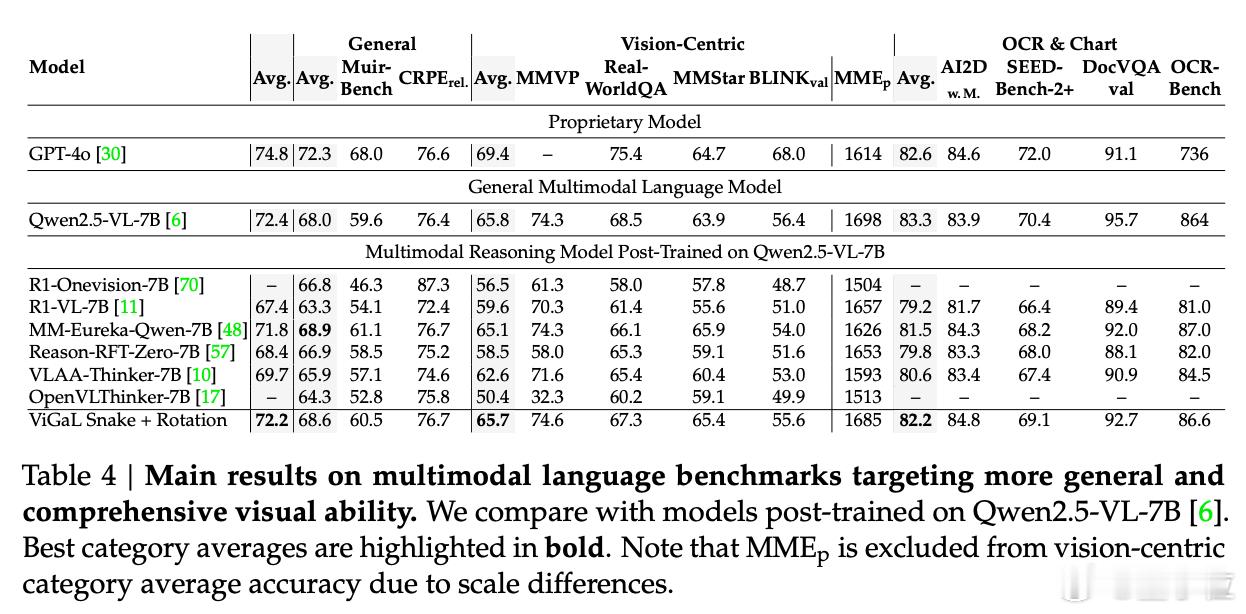
不过,在通用任务上,ViGaL的表现暂时还是落后于基础模型,与GPT-4o也有几个百分点的差距。【图5】
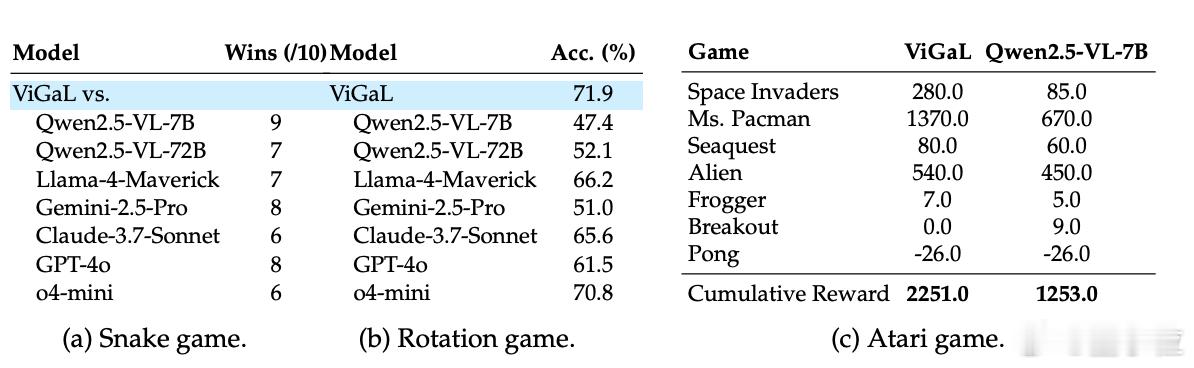
最后,研究人员让ViGaL挑战与其训练环境迥异的Atari游戏,其得分近乎达到基础模型的两倍,展现出了显著的零样本泛化能力。【图6】
值得一提的是,研究团队还发现,用带奖励的强化学习来训练模型,在数学推理和几何任务上效果显著,性能提升了12.3%。
而如果用相同游戏数据进行传统的“监督微调”,反而会使准确率下降1.9%。
感兴趣的朋友,可以阅读论文原文: