
短短一个月,腾讯混元 3D 生成模型又升级了一次,从 v2.0 版本到 v.2.5 版本,据腾讯宣称 v2.5 版本在建模精细度上大幅提升。加上免费试用次数翻倍,从 10 次变为 20 次,知危马上冲过去做了测评。
早在 v2.0 版本于上个月开源的时候,知危就做了一些尝试。通过在线体验,知危实测能够通过 v2.0 版本获得不错的 3D 对象,其中分别验证了单图生成、多视图生成和骨骼绑定的效果。
比如单图生成《 数码宝贝 》中的暴龙兽,还原度简直不要太高。
输入图:

暴龙兽( 图源:DeviantArt )
输出:
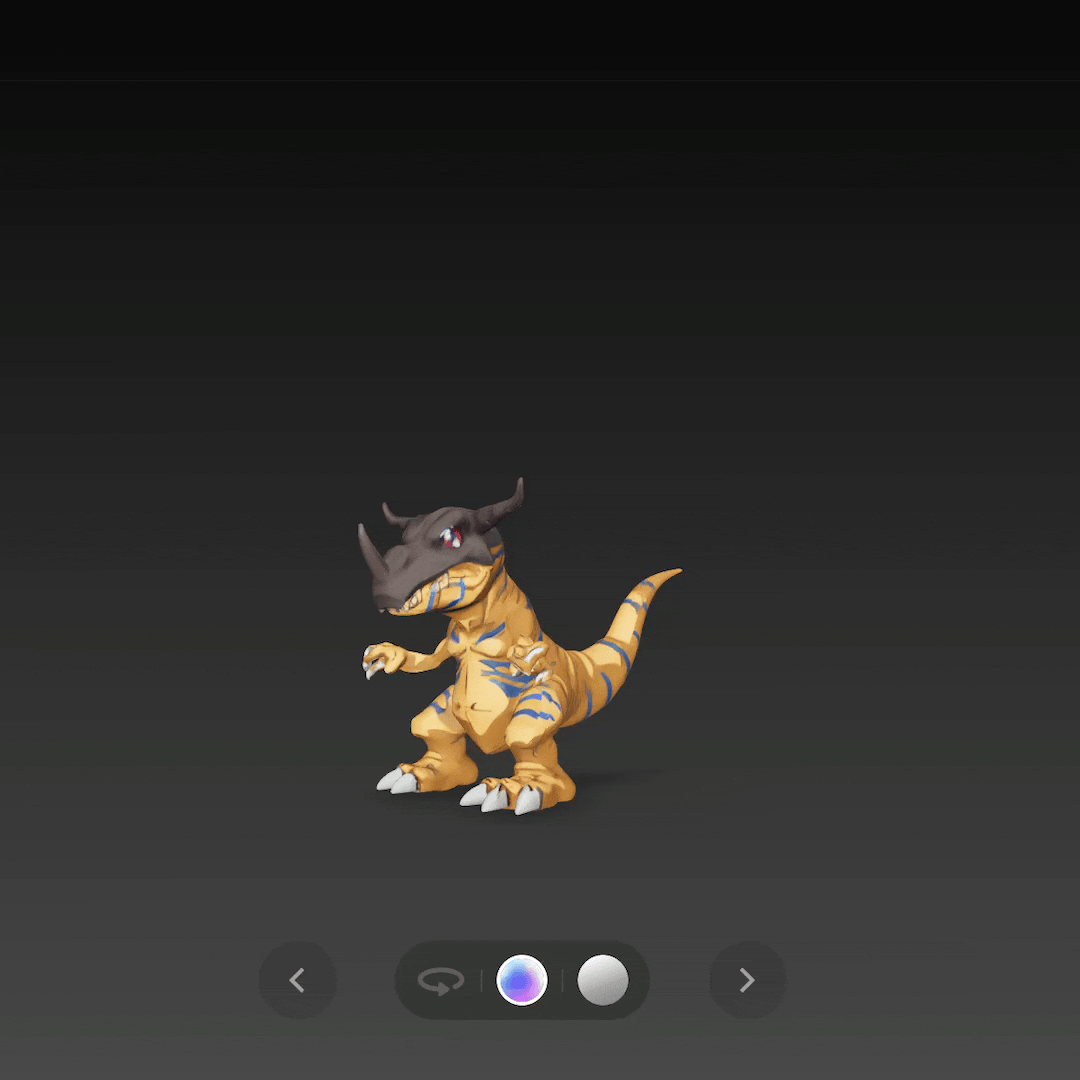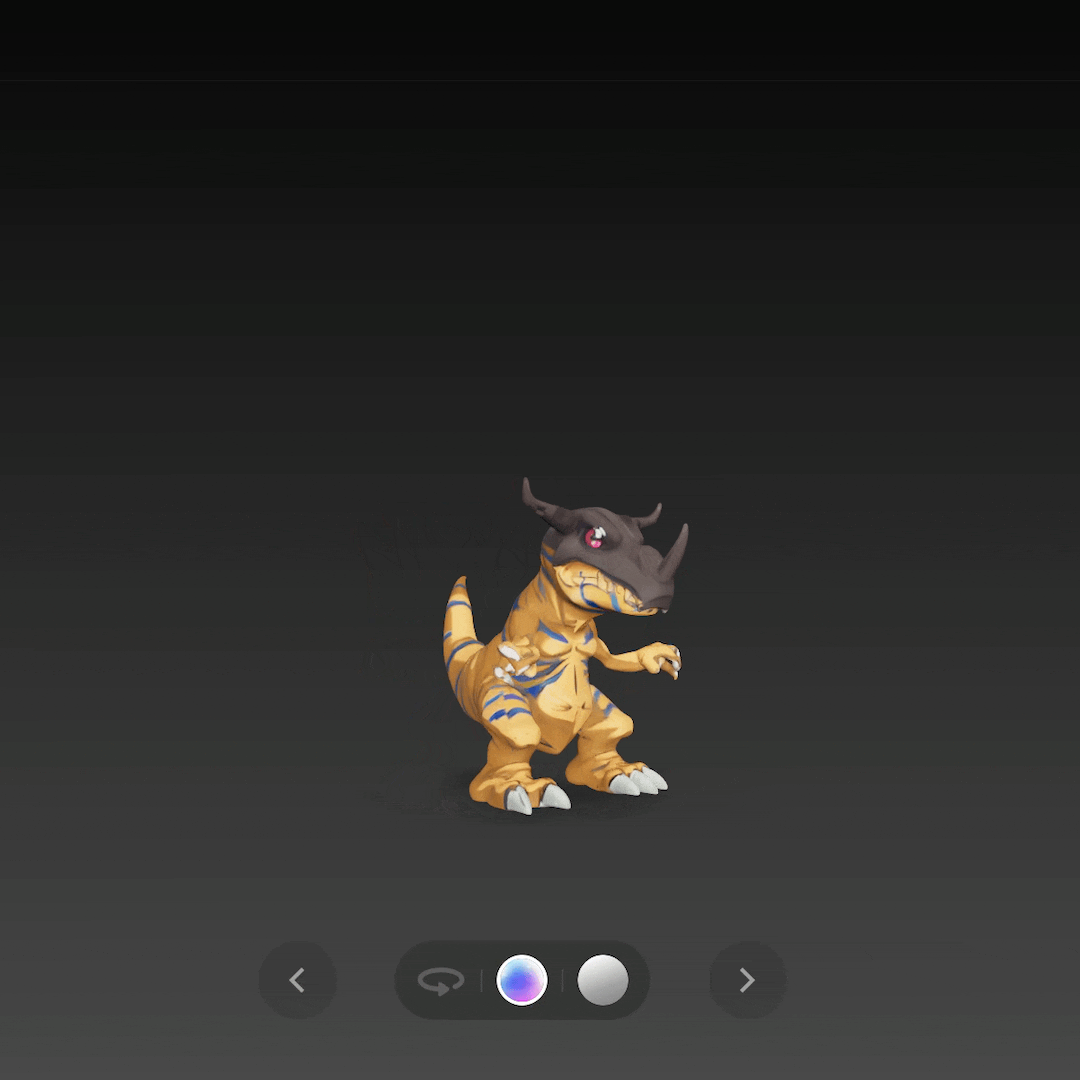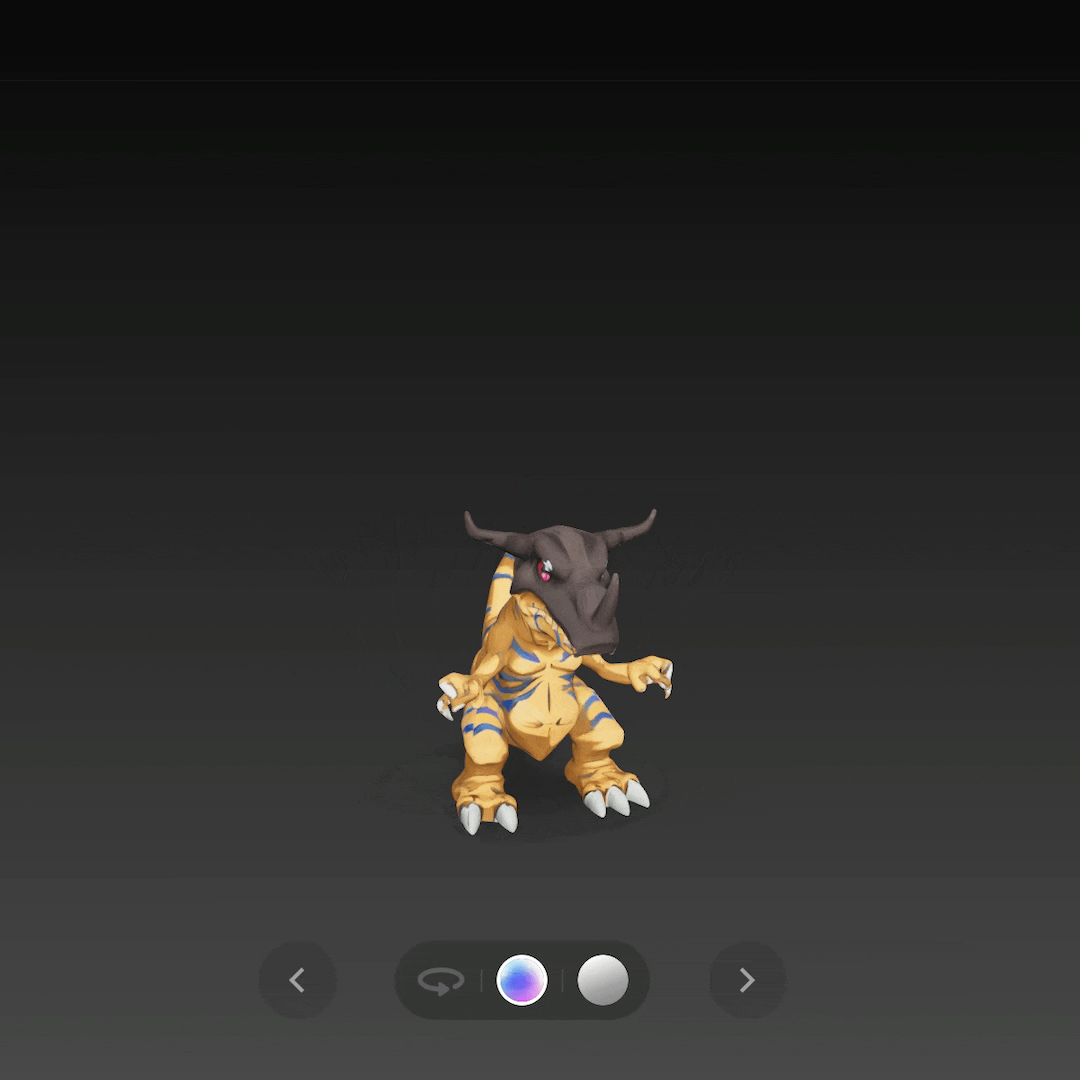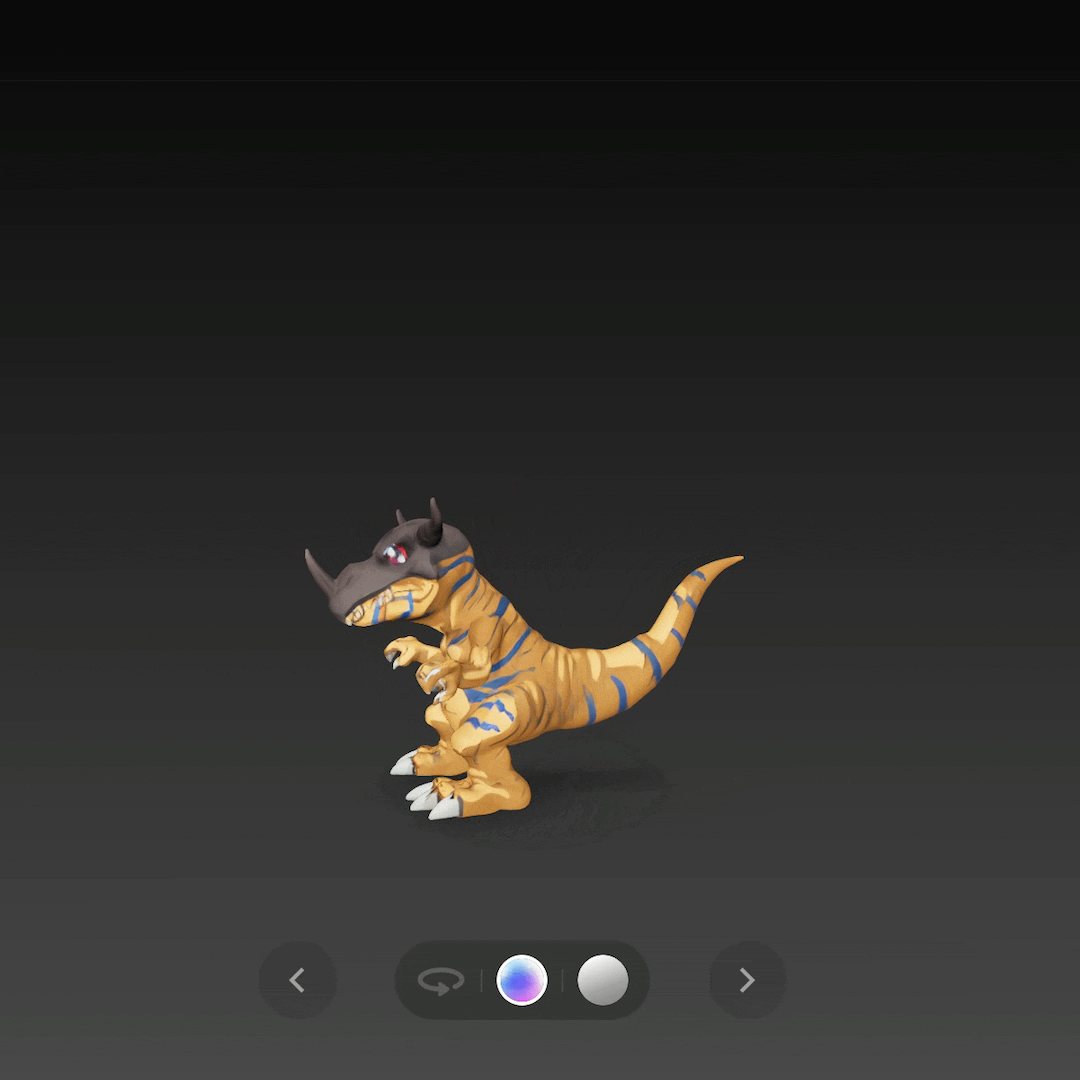
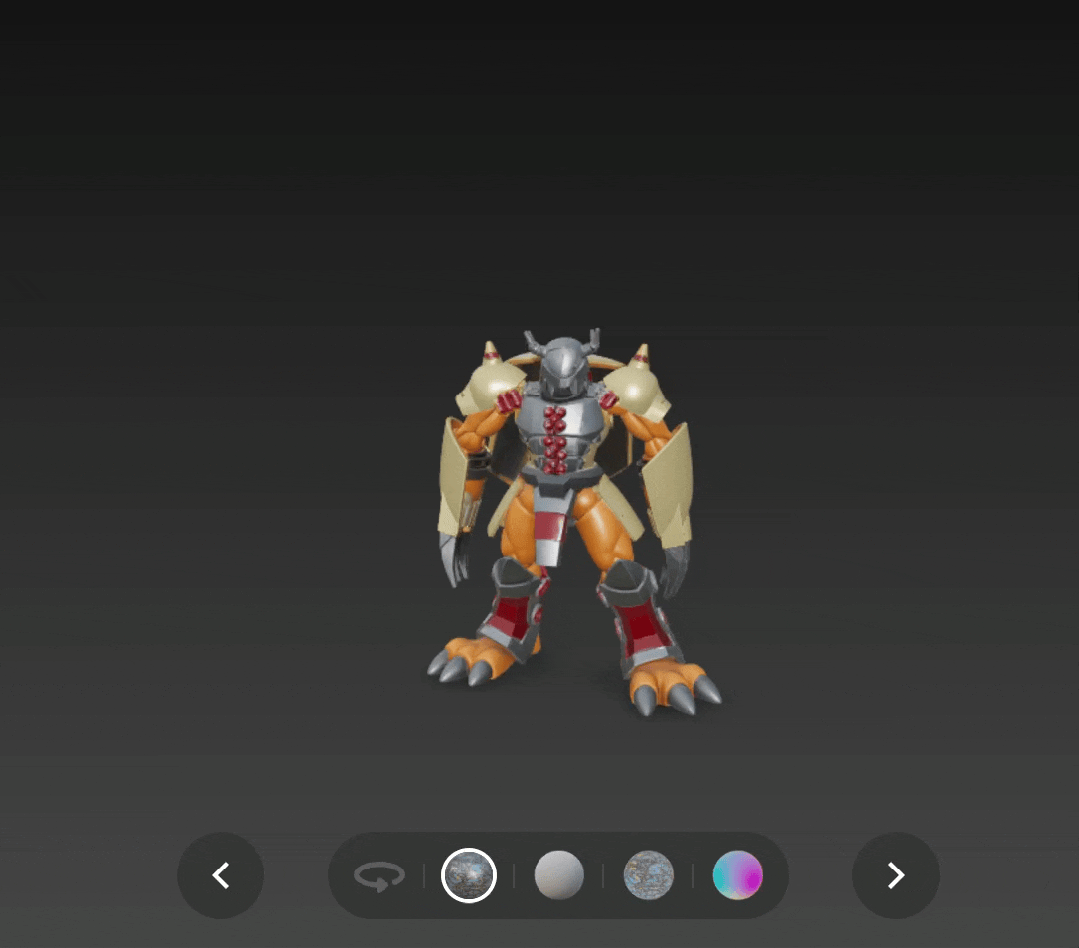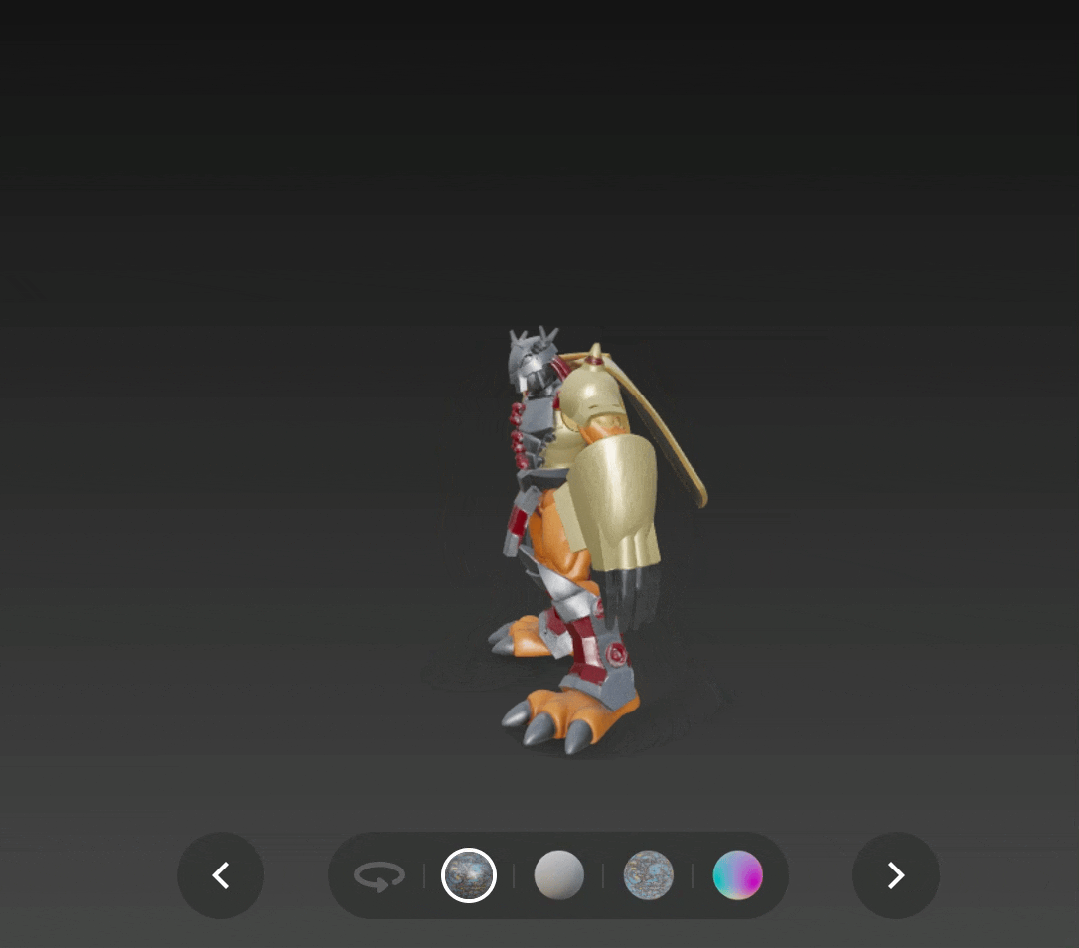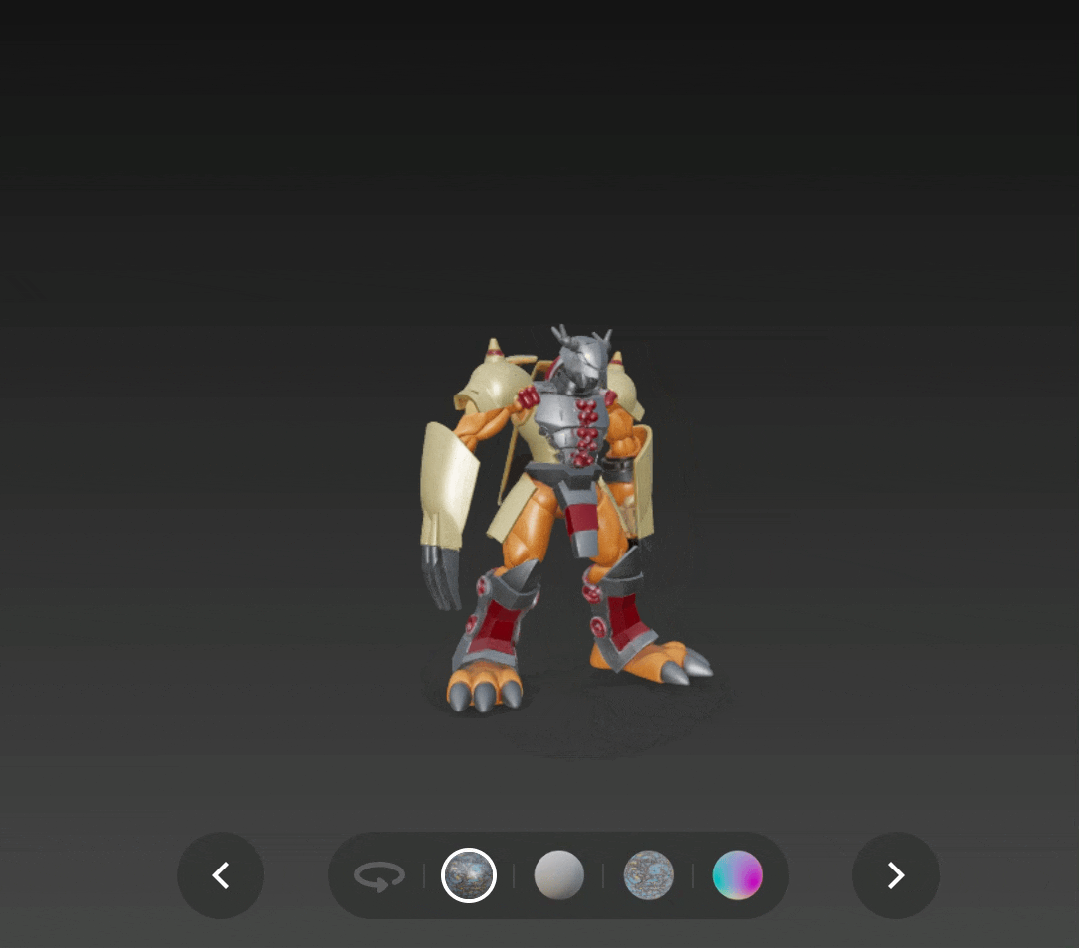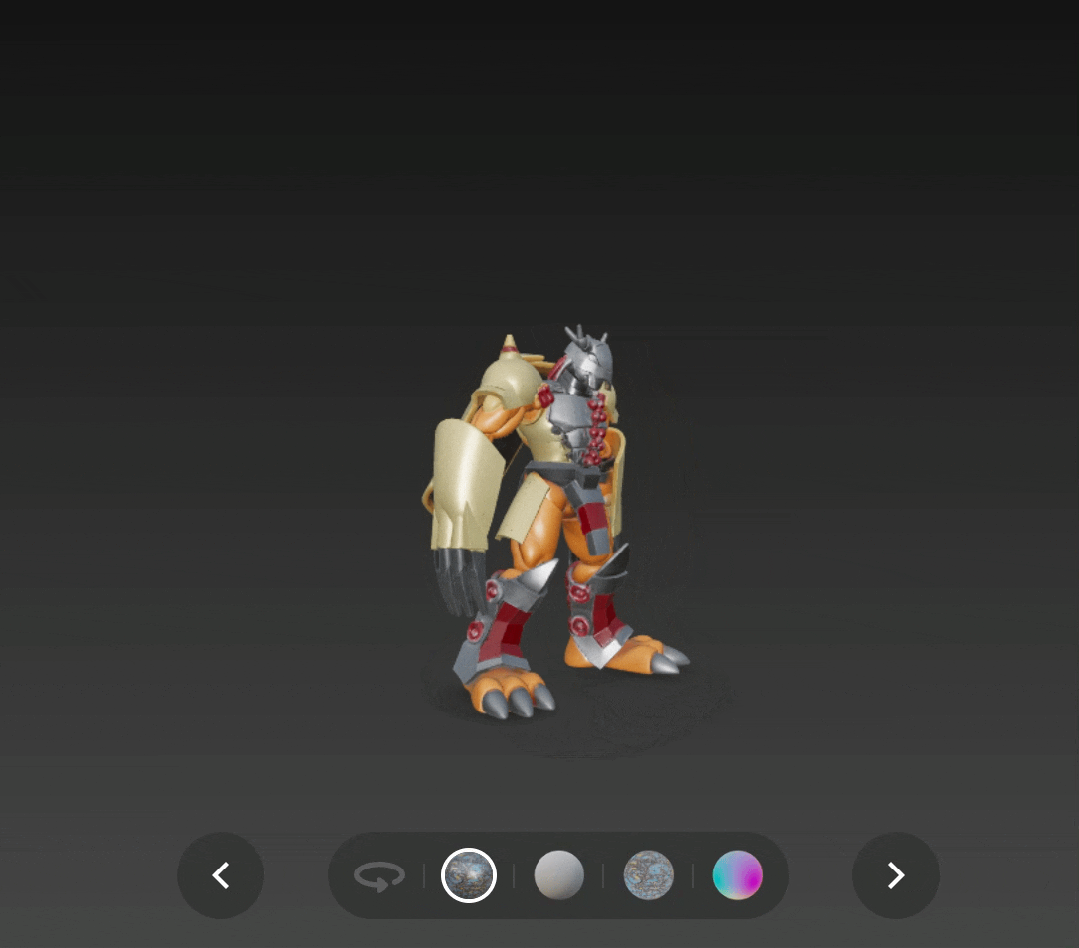
再通过单图生成一个战斗暴龙兽,不仅是整体形态,连盔甲的嵌套结构都还原了出来。
输入图:

战斗暴龙兽( 图源:eBay )
输出:

接下来是通过多张照片生成的粉色史迪仔,黄色小围巾其实不是娃娃自带的,而是后面绑上去的,也还原的很好,后脑勺的花纹没有还原有点可惜。
输入图:




输出:

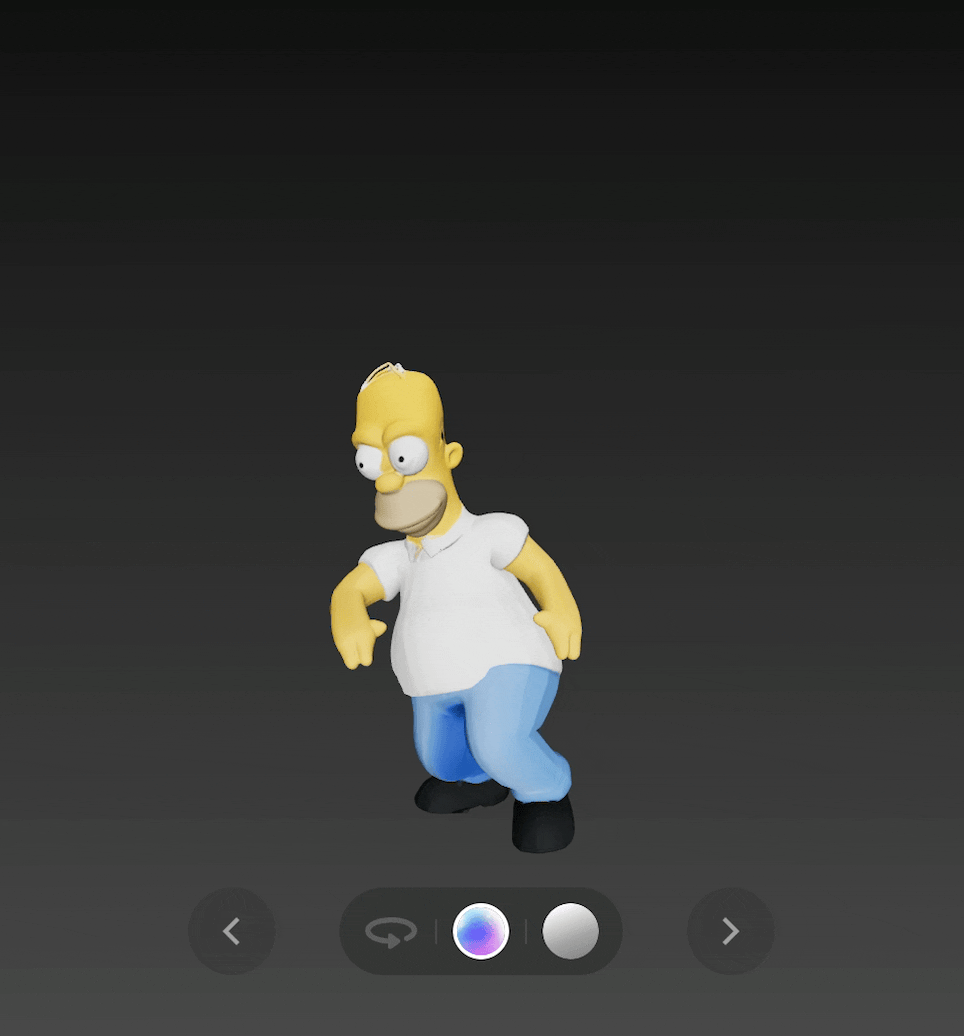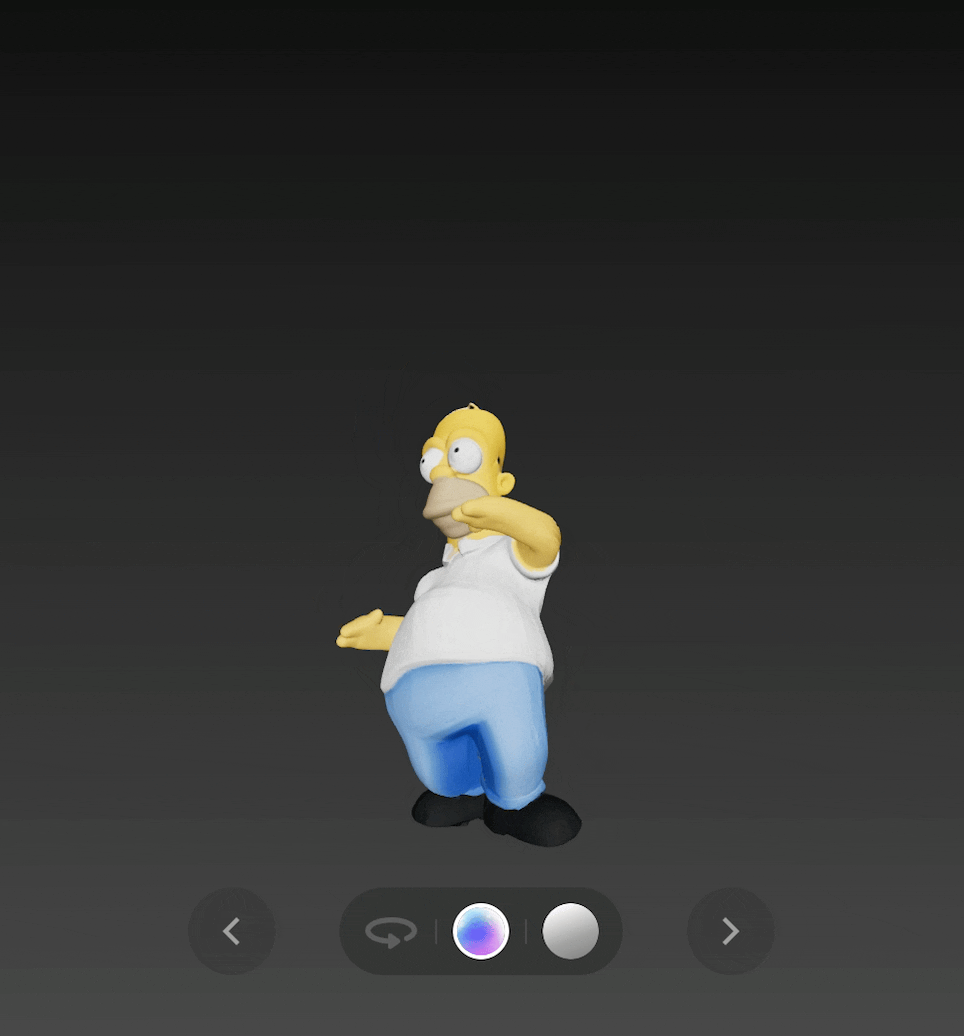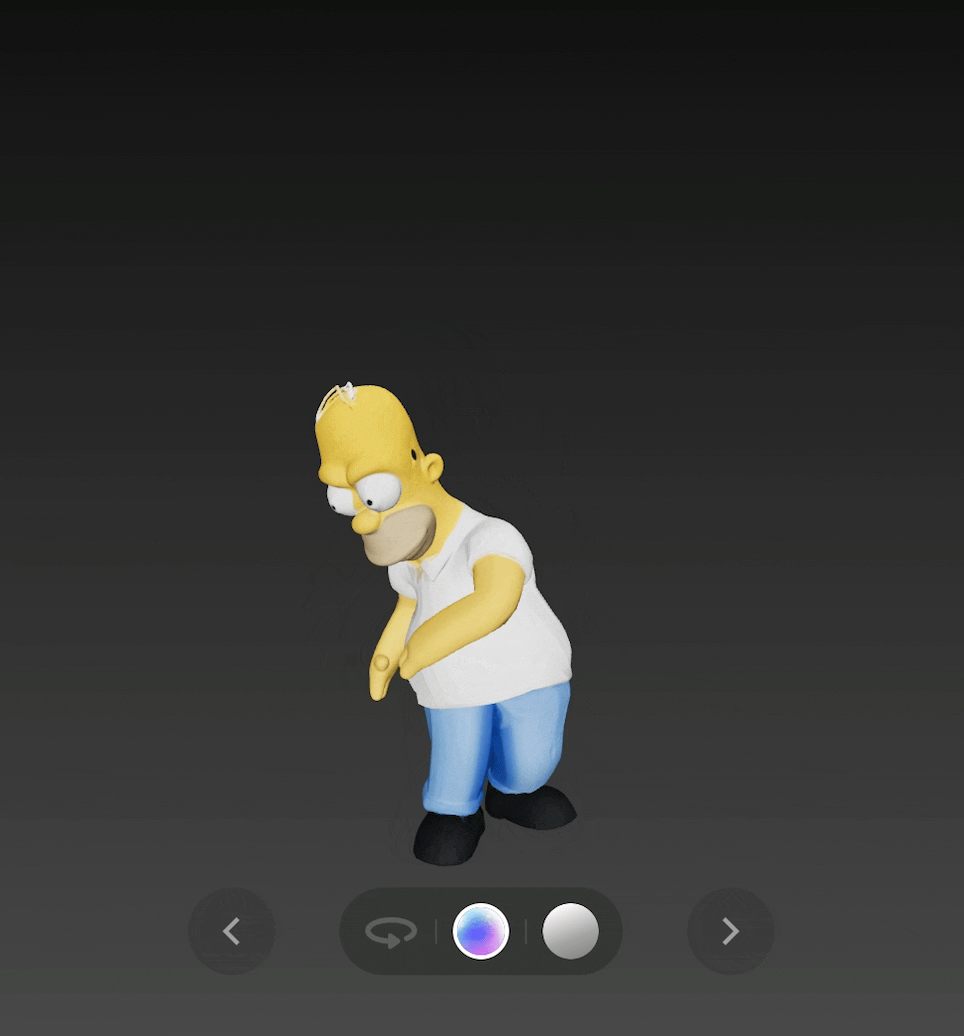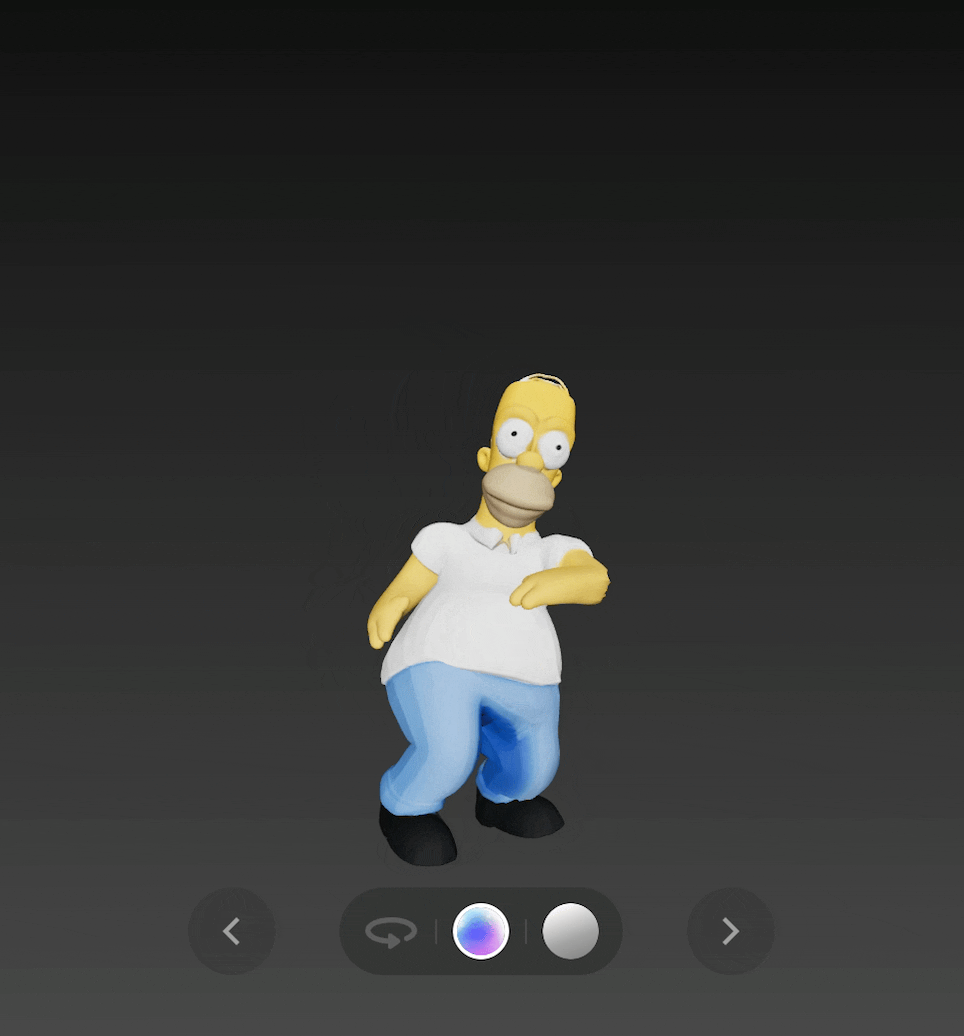
最后是《 辛普森一家 》中的 Homer,v2.0 不仅生成了完整的 3D 模型,还可以通过绑定骨骼,让 Homer 跳起舞来。
输入图:

Homer Simpson( 图源:TurboSquid )
输出图:
据了解,混元 3D 的开源生态已经比较丰富,包括 1.0、2.0 基础模型及基于 2.0 模型的加速、多视图和轻量级模型均已开源,Github 总 star 数超 1.2 万。
截至目前,v2.0 版本已在 Hugging Face 上的 “ image to 3d ” 模型类别中达成了总下载量第二的成绩( 下载量 529k 次,仅次于 TRELLIS-image-large 的1.01M 次 )。
相比 v2.0 版本,混元 3D v2.5 模型总参数量从 1B 提升至 10B,有效面片数增加超 10 倍,表面更平整、边缘更锐利、细节更丰富,有效几何分辨率达到1024,“ 就像从标清升级到了超清画质。”
比如这张官方展示的法线图,人脸、身体、翅膀都有非常清晰的轮廓和细节结构。

再看看知危的实测效果,对比 v2.0 版本和 v2.5 版本的暴龙兽法线图,在皮肤纹理、头骨边界甚至角的纹理等细节的差距非常明显。


贴图质量也更加好,阴影效果很明显。
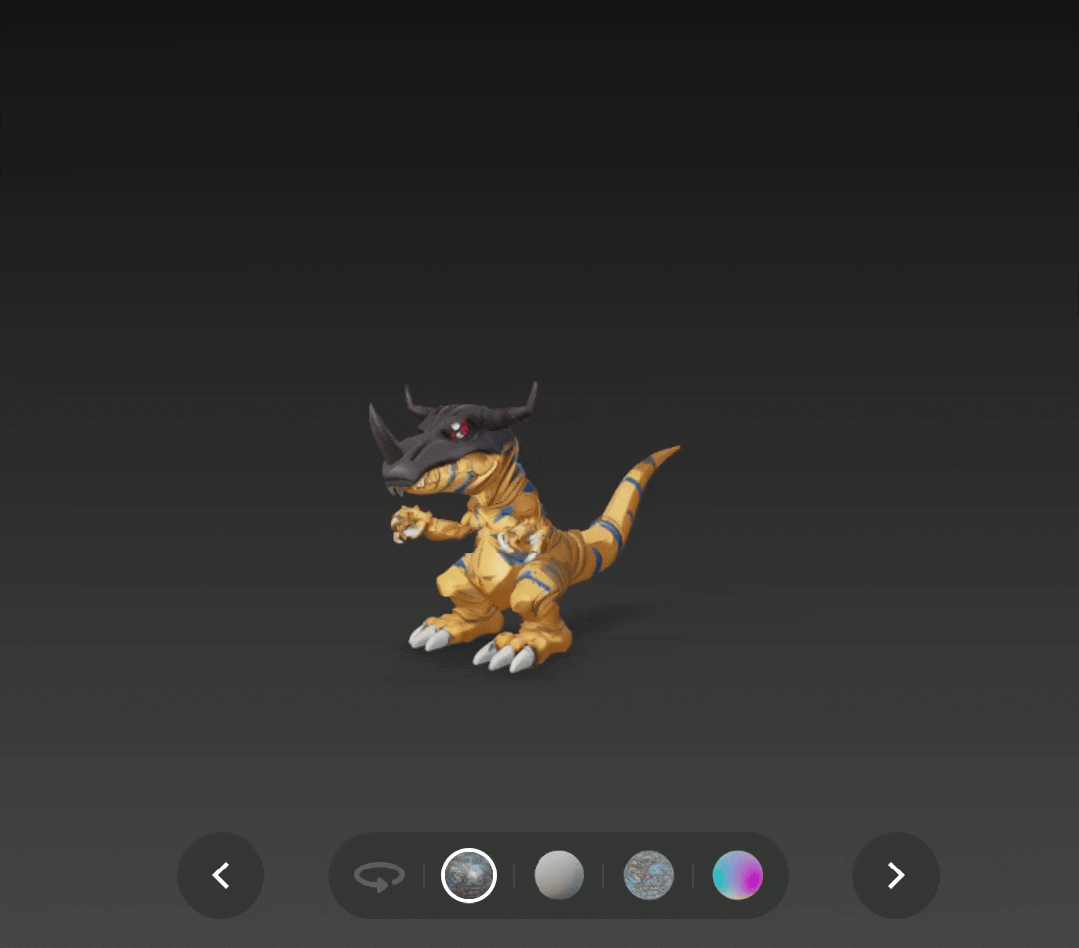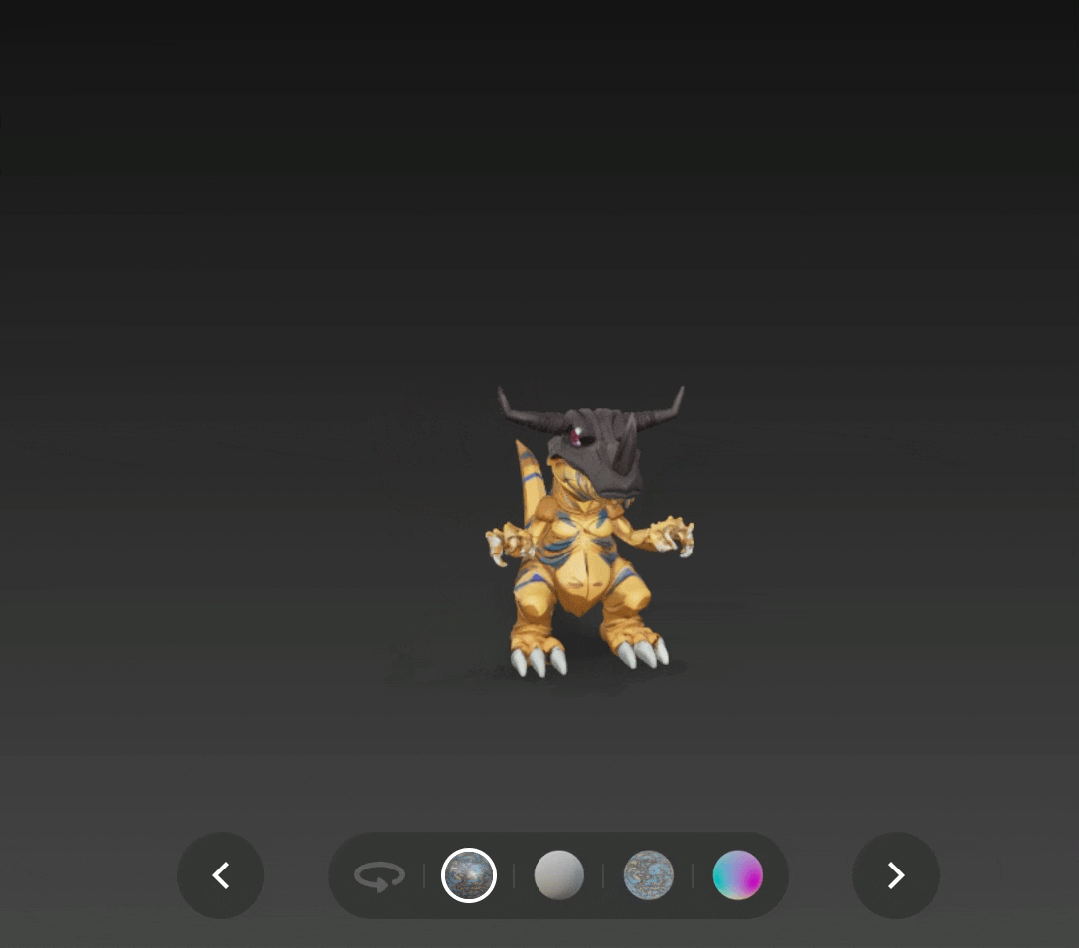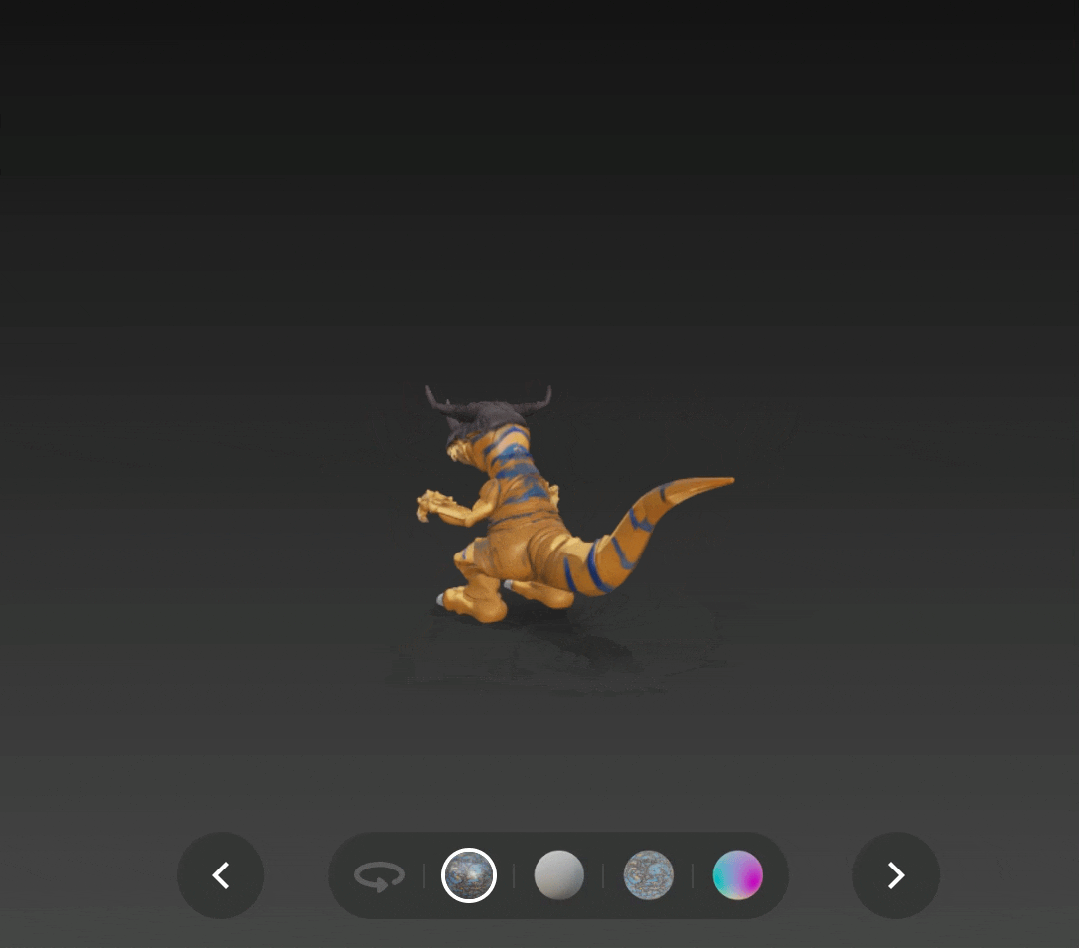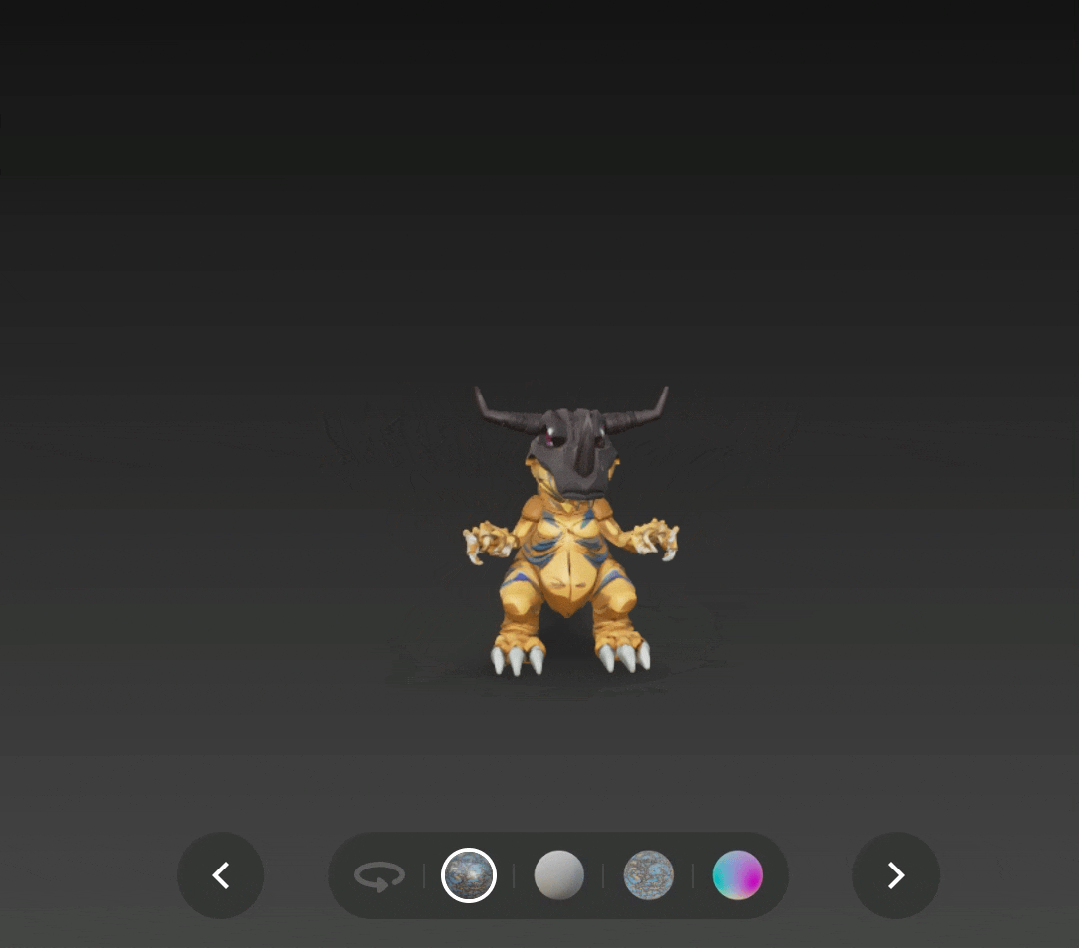
通过 v2.5 版本生成并添加了 PBR 贴图的战斗暴龙兽,也更有了实体模型的感觉,只是这次头盔上的角没有还原是个小遗憾。
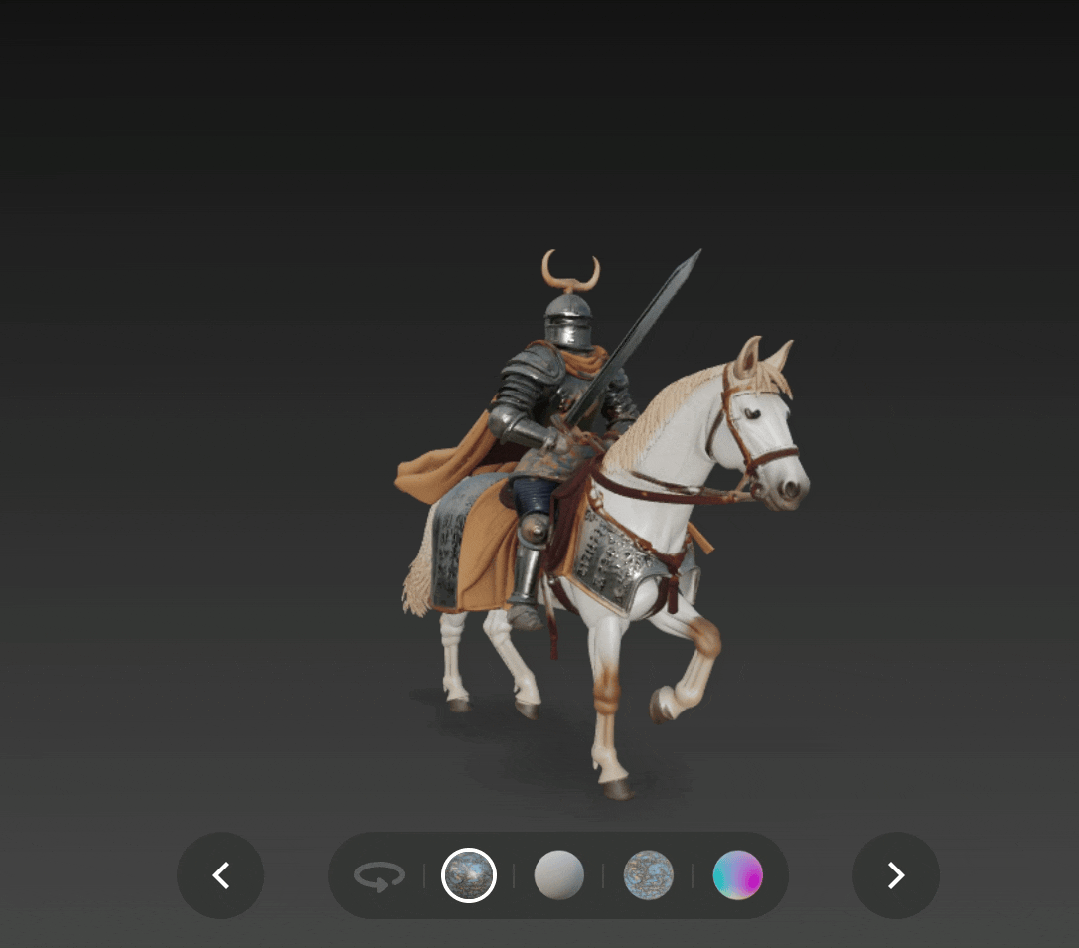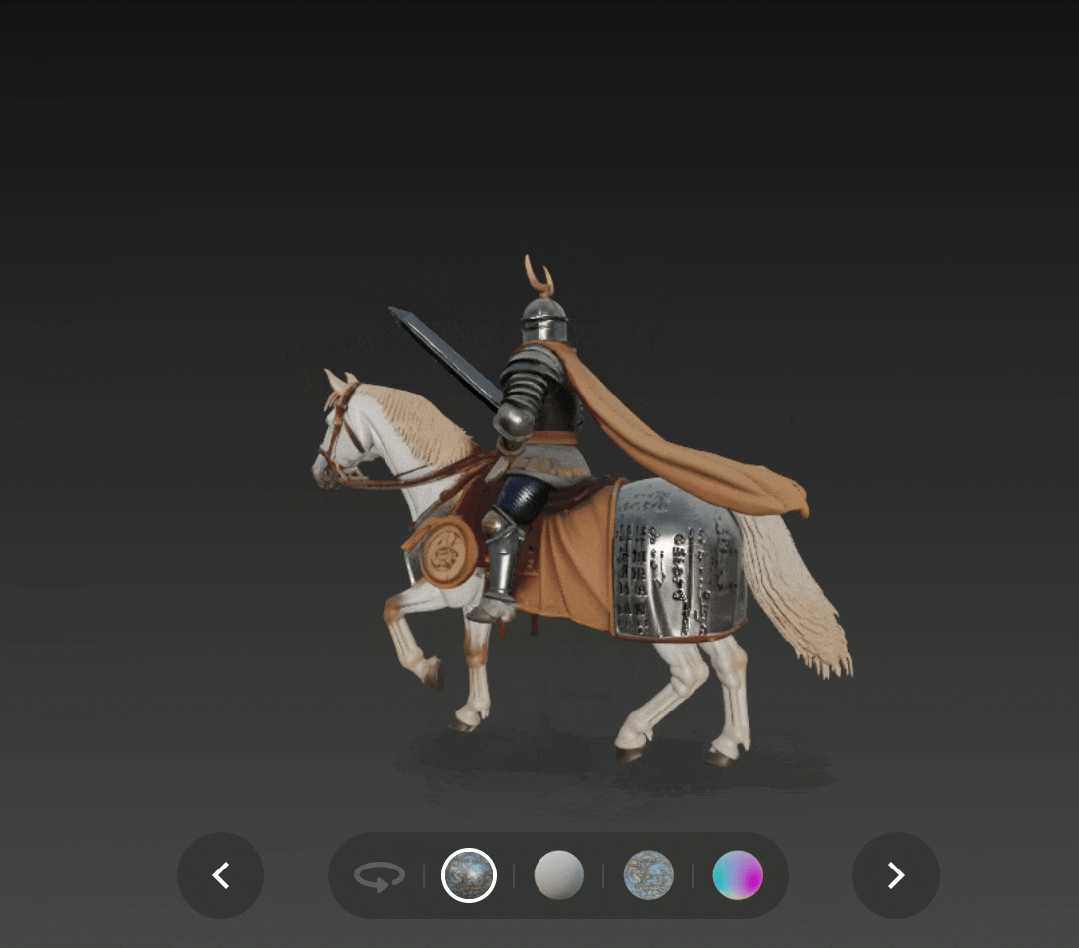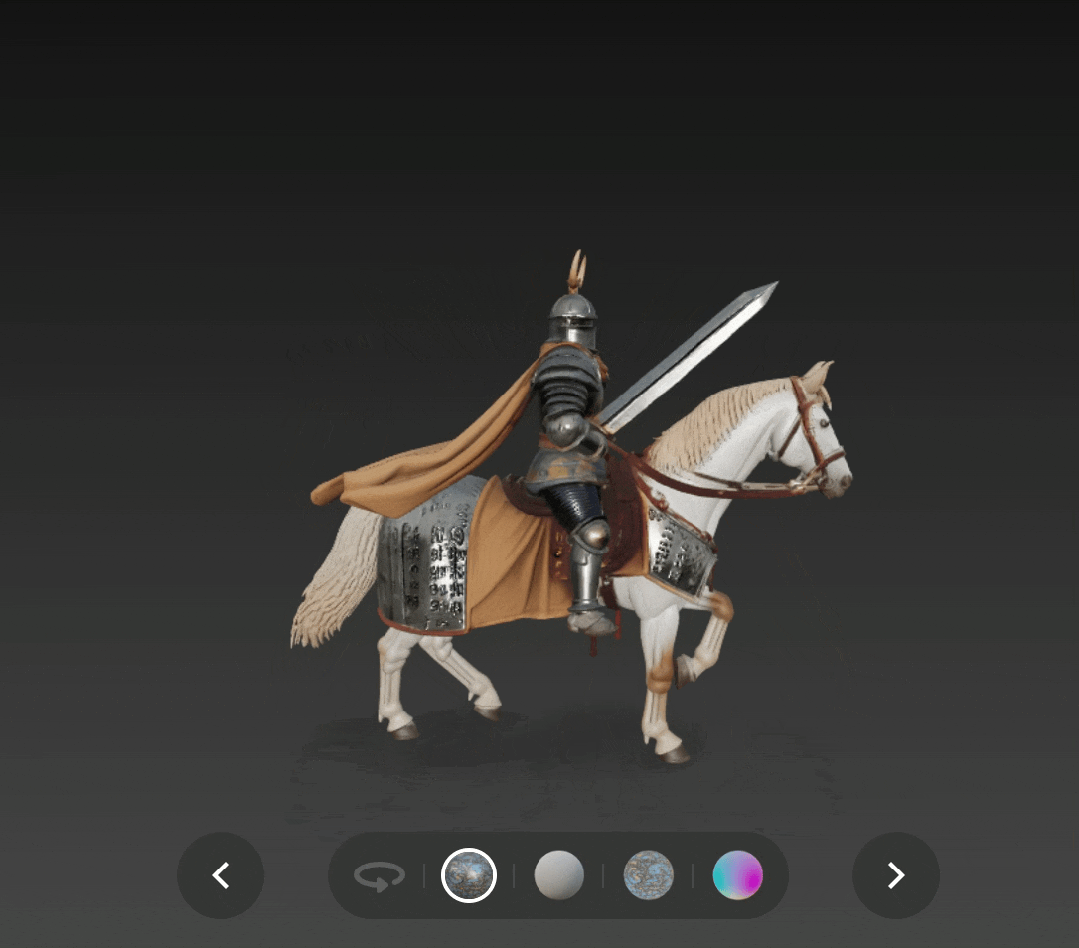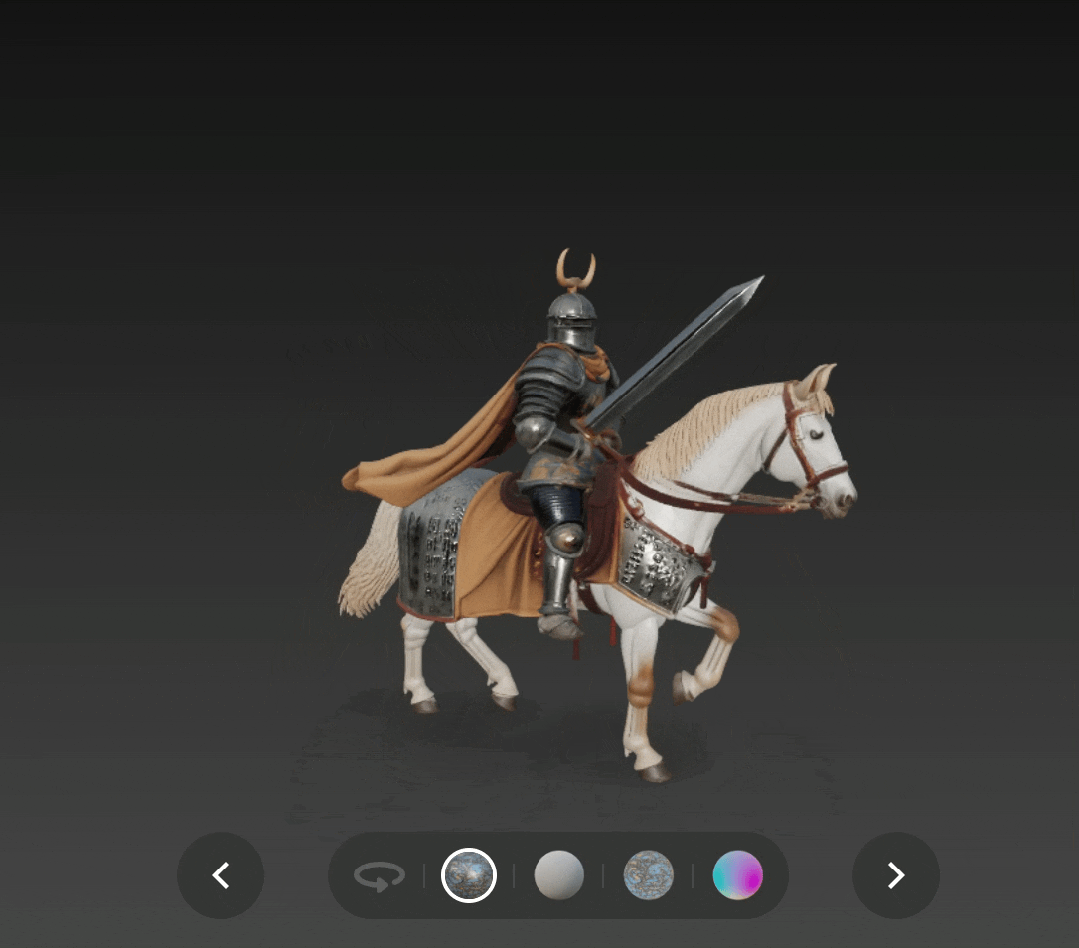
我们还尝试了文生 3D,下图是通过文生 3D 得到的中世纪骑士持剑骑马的形象,添加了 PBR 贴图,除了战马身上的布匹不够破烂、角状头盔羽冠成了角之外,基本都遵循了提示,纹理质量和光影效果也很好。
提示词:
一位中世纪骑士骑着战马驰骋,他身披华丽却饱经战火的盔甲,披着飘逸的斗篷,手持巨大的剑。骑士的盔甲上镌刻着符文,部分已然失去光泽,头盔上窄窄的面甲上饰有角状的羽冠。战马肌肉发达,身披金属铠甲,披着破烂的布匹。
然后是 3D 人脸生成,这是单图生成的 3D 版莫扎特。

对比原图,可以看到虽然 3D 对象本身质量很高,但和本人没那么像,结合社区的反馈,混元 3D 目前对人脸细微特征的还原度确实还不够高。

莫扎特画像( 图源:维基百科 )
最后提醒一下,在做单图生成的时候,输入图片的视角很重要,最好是 45 度侧视角,这样能包含足够多的对象信息。如果是正视图,是有较大概率失败的。
比如在 v2.0 版本下生成的亚古兽,头部过于扁平了。
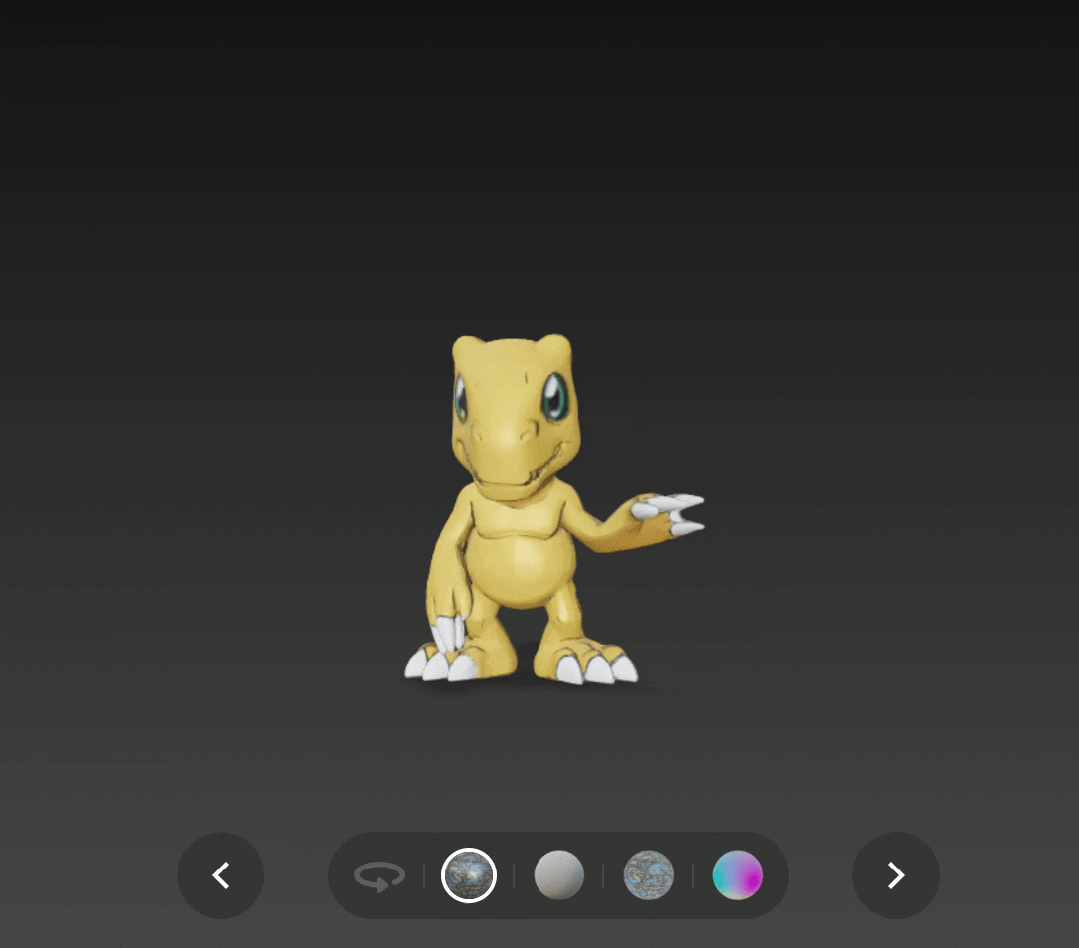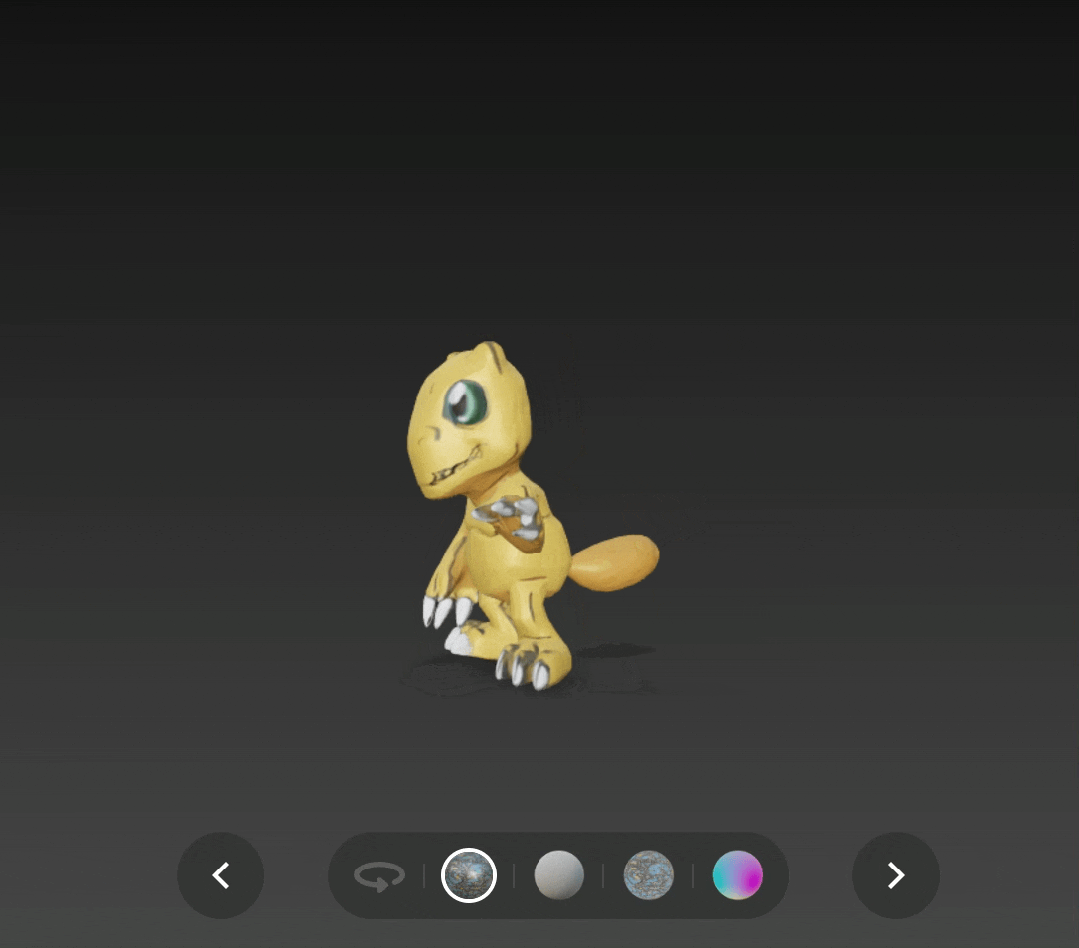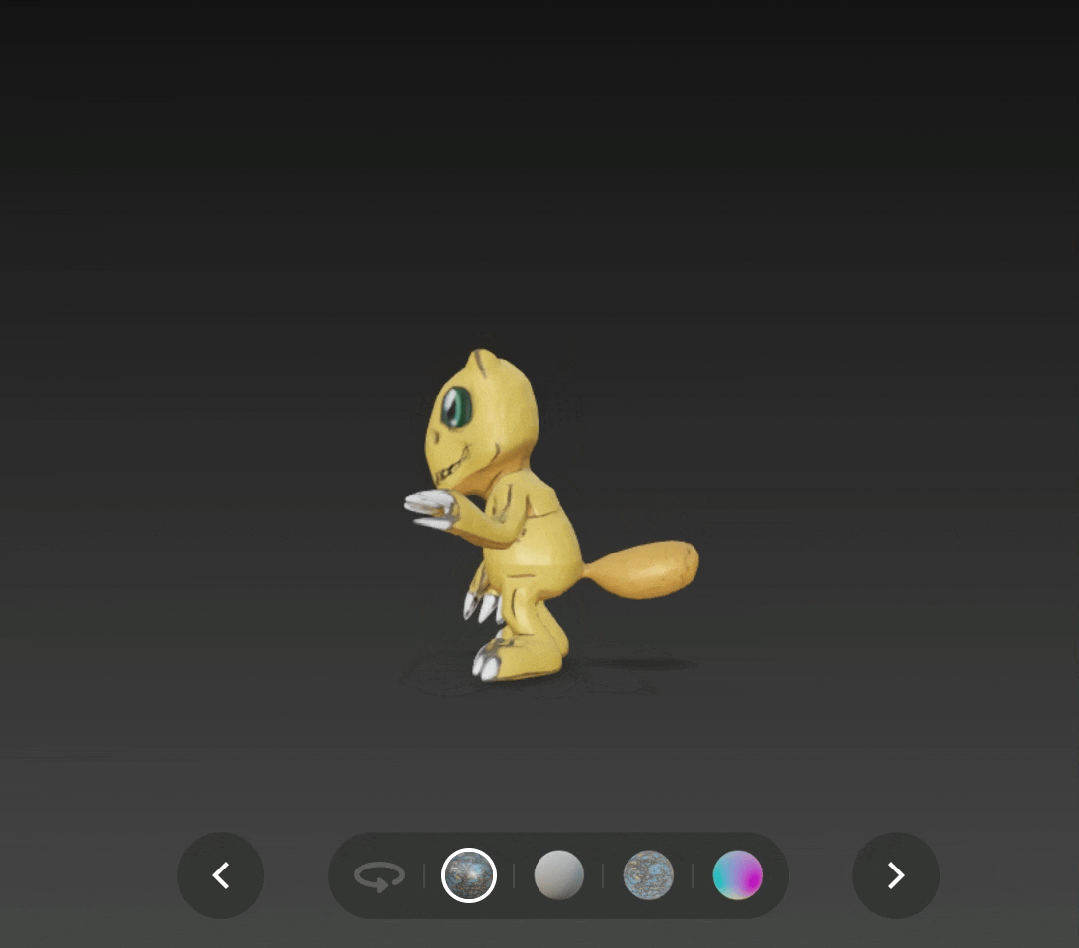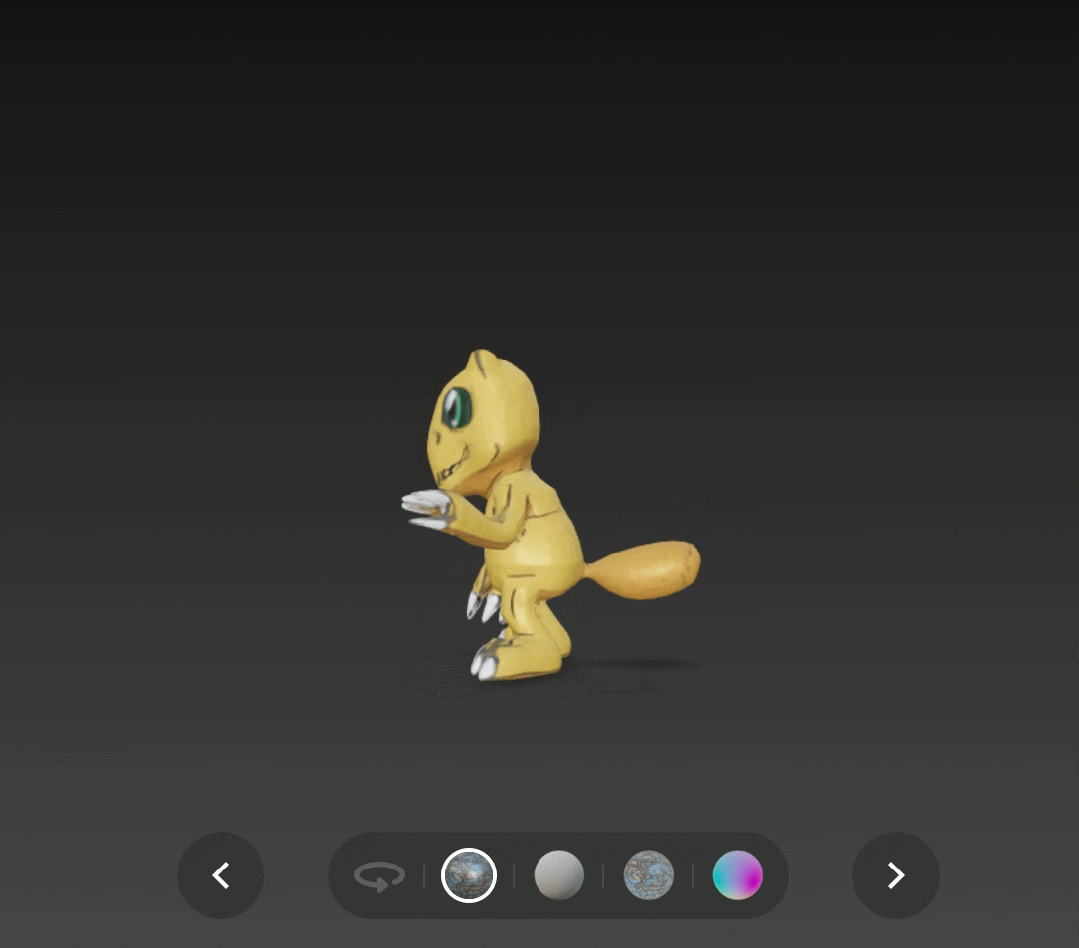
输入原图是:

亚古兽( 图源:DigimonWiki )
这仅仅是一次轻量级的测评,混元 3D 还有大量功能比如智能减面、纹理生成、草图生 3D、小游戏创作等可以去尝试。
AI 生 3D 技术发展迅速,但其实整体还处在非常早期的阶段,真实性和可控性都是初级水平,这也是目前在技术层面解放开发者创意发挥的最大障碍。
眼下,越来越多独立开发者或小型工作室将AI生成内容嵌入游戏中,以增强游戏内容的多样性和不确定性,以及降低开发成本,比如“ Infinite Craft ”、“ ChatNPC ”、“ Talking Coin ”、“ telAIphone ”、“ 沙威玛传奇 ” 等。其中,“ 沙威玛传奇 ” 大量使用了 AI 作画、AI 作曲、AI 配音。
然而,不同模态的 AI 生成技术,要整合进复杂的人类工作流,都要先后经历真实性和可控性两道大关,目前各自发展成熟度差距明显。文本生成已经到探索强推理的阶段;图像生成刚刚见证 GPT-4o 带来的精准文字、图表生成能力;视频生成的角色和场景一致性不断增强,但动态和物理理解仍有欠缺,尚未迈过第一道坎。
为深入了解 AI 生 3D 技术的场景落地现状和商业化前景,知危和腾讯混元技术专家就该主题进行了沟通,并将场景聚焦在游戏行业。
技术层面,AI 生成 3D 的技术路线并未固定,比如模型架构是采用扩散模型、归一化流还是 GAN。
腾讯混元也向知危表示:“AI 3D 在技术层面存在的探索空间还非常大,在各方面都存在显著提升模型能力的可能性。数据层面是老生常谈,不仅仅是量,还包括如何挖掘已有数据里额外的有效信息。”
“ 生成模型现在主流的方案包括一阶段或多阶段,以及生成 3D 到底是使用格点相关的表达还是点云相关的表达,各自有各自的优势和局限。另外,生成模型如何引入正确的输入条件,如何进行合理的 scale-up( 规模化扩展 ),仍然有很多值得探索的问题。”
“ 最后,如何对一个复杂模型或者场景模型进行有效的分部件生成并仍然保有可端到端学习的可能,也是一个重大的挑战。”
尽管路线远未成熟,但按照过往经验,不同方向的 AI 技术都有互相促进的可能。包括机器人、图像生成等,大语言模型在各种领域都有作为基础模型增强AI生成的潜力,比如智元机器人 GO-1 将视觉大语言模型接入决策模型中。
腾讯混元团队认同这个思路:“ 模型的路线并非非此即彼,往往相互间都有可以借鉴之处,应该说现在技术的发展确实多面开花,如何集成各自优秀的能力并去除各自的局限,也是一个重要的命题。”
对于 3D 生成,目前与大语言模型的结合主要在于开发工作流方面,而不是底层的模型层面,但已经能带来大量的收益。
首先是提升开发交互的体验并降低使用门槛,腾讯混元表示:“ 大语言模型的快速发展确实对 AI 3D 生成产生了显著的促进作用,尤其在自然语言交互的 3D 生成控制、场景逻辑推理等方面。”
“ 举例子来讲,在文本生成3D物体模型的场景,语言模型一方面可以加强文本到3D指令解析的准确性,将相对模糊的文本描述转换为更具体的3D模型生成参数。" 这对需求并不特别明确的开发者比较友好。
“ 另一方面,通过多步骤指令拆解可以生成可控性更高的 3D 模型。” 也就是说对于需求明确而复杂的开发者,借助大语言模型能提升复杂意图理解能力,显著降低开发者工作量。
描述 3D 物体的语言这一中间模态是非常关键的一部分,可以是专业化的自然语言,也可以是专业开发引擎的代码。比如 Meta 提出的 SceneScript,可以将视觉输入转换为描述建筑布局、物体边界框的语言,适用于 AR 应用;近期由于 Claude 3.7 Sonnet 的发布,社区里尝试用 Claude+MCP+Blender 的组合来生成 3D 资产,也是打开了新思路。这类方法专注于强化语言的精确性、逻辑性,以此保证生成的 3D 资产满足实用需求,并避免了类似扩散模型生成 3D 资产的不可预测的各种小缺陷。
但腾讯混元向知危指出了这类方法的利弊:“ 结合语言模态,对一些垂类场景( 比如建筑语言/CAD等 )可以给模型带来比较有用先验的帮助。不过对于更通用的场景,缺少足够结构化的语言模态表示,语言模态更多只是起到辅助的作用。”
“至于 Claude+MCP+Blender 的组合,这是一个产品的解决思路,不是一个技术路线。从产品维度也存在其他解决方案的可能,这需要我们与行业界尤其是高价值游戏制作者进行碰撞逐步演进。从技术路线来讲,仍然需要考虑模型的生成稳定性、质量、组件分离和可编辑性。”
业内也有不少围绕通用的视频大模型能否取代专用的 3D 生成模型的讨论,特别是在谷歌 Genie 2、李飞飞团队 World Labs 的开放世界游戏研究成果发布、以及近期视频生成模型的飞跃式进步的背景下。类似地,GPT-4o 的图像生成能力也实现了通用模型对专用模型的降维打击。
但腾讯混元认为,这两者还是有区别的,“ 视频用于观看,3D 资产用于实时交互、建模管线使用等。视频大模型可以为 3D 生成模型带来额外的收益,但是纯粹的替代是不可行的。因为视频模型到 3D,本质上是涉及一个 2D 到 3D 的重建过程。视频难以处理自遮挡、几何结构、拓扑等游戏管线里必须要解决的问题,因此无法替代 3D 生成模型。对于游戏管线需要的资产,视频模型可以用于做原型验证,但不会用于实际的游戏实时操控。”
实际上,微软就曾在 WHAM( World and Human Action Model,世界与人类行为模型 )这项研究中探讨了视频模型用于原型验证的可行性。视频模型对于原型验证提供了快速便捷的方案。
另外,WHAM 也特别强调了迭代实践也就是交互联动的重要性。快速地呈现效果非常重要,WHAM 访谈的游戏开发者表示 “ 在我们看到正确的输出之前,很难知道它是什么 ”。
腾讯混元也向知危强调了这一点,“ 一个优秀的生成模型要拥有好的编辑性,有可控的质量和修改能力,这一点整个领域还处在早期。”
密集的交互联动目前是 AI 深入人类工作流的最佳模式,完全交给 AI Agent 还是不够可靠,可能导致错误难以追溯。
专业的游戏创作者真正关心的是微创新,“ 细节才是真正令人惊叹的游戏体验的关键 ”,他们需要快速地在不同的迭代之间进行动态的来回探索,以汲取灵感并尝试融合不同元素的可能性。
当下不少 AI 产品都在强调 “ 一键生成 ”,但这是一种粗糙的创意探索方式,主要面向小白用户。如果一个 AI 工具能够限定自己的边界,提供最具可靠性的中间输出,并能无缝接入后续的非 AI 工具,或者能利用 AI 进行细微的迭代测试,才称得上是 “ 成熟稳重 ” 的 AI 产品设计,专业开发者才会为此买单,不过这对于 AI 模型的能力要求也很高。
腾讯混元补充道:“ 随着大语言模型本身能力的持续提升,其可以辅助开发者生成更符合现实物理规律或规则的 3D 场景,并且可以与场景中的行为通过自然语言的方式进行交互联动。”
AI 3D 生成在实际落地中如果不能直接用于开发生产,也会将其用于辅助开发或 Demo 测试上,当然,相比视频模型,AI 3D 生成的场景渗透更加深入,“ 这个问题需要区分游戏类型,对于轻小游戏,混元 3D 搭建了游戏 AI 3D 管线,生成的资产在轻/小游戏的场景,基本上已经达到实际生产可用水平了。而在一些对建模精度要求更高的场景,AI 3D 生成的结果会应用于快速原型验证、Demo 搭建以及一些背景、远景物体的生成,可以缩短游戏迭代的周期。而对于高精场景的核心资产生成可用方面,我们还在继续努力。”
综上,AI 生 3D 技术路线尚未统一,产品特性比如多轮可编辑性等方面的局限性限制了产品的全面创新。而在不同类型的具体场景中,其应用深度也是有所区别的。
腾讯混元向知危表示:“ 当前全球 UGC 游戏行业的市场规模已经超百亿美元,年增速也在不断增加。其中,AI 生成 3D 工具的渗透率在快速提升,主要的商业模式包括玩家游戏内购以及在 UGC 内容中植入品牌广告进行盈利。玩家游戏内购有较大的高利润率,且用户付费意愿较强,但依赖用户活跃度和创作生态;广告盈利更适合用户基数大的平台,但在一定程度上会影响用户体验,可能导致用户流失。”
UGC 只是娱乐,开发才是真试炼场。AI 3D 生成在专业开发群体中接受度不高,也是不争的事实,比如生成人脸 3D 模型的拓扑精准度过低,很多开发者抱怨修改难度太大,甚至高于从零开始构建的成本,腾讯混元表示:“ 更具体来说,是小尺寸人脸拓扑精度较低。这是 AI 3D 生成的普遍现状,这也是我们目前正在攻克的一个方向。”
“ 小尺寸人脸占身体比例过小,很大概率会非常模糊,所以用 AI 生成和从头建模没太大区别。当然对于一些大头照,我们的模型还是可以获得一个有一定细节的人脸,还是能加速建模流程的。”
综合来看,从 UGC 应用到专业模型开发,其技术难度从易到难,在业界看来,是一条有效的落地路径,“ 从易到难的场景分类可以是游戏 AI 3D 生成逐步落地、反馈迭代的有效方式。逐步落地意味着从较简单的场景开始,逐渐扩展到更复杂的场景,以确保技术的可行性和有效性。这种渐进式的方法可以帮助研发团队逐步适应和应用游戏 AI 3D 生成技术,同时从用户和市场的反馈中不断改进和迭代。
“ 其它落地路线可能是针对游戏开发痛点进行单点突破,并展示游戏 AI 3D 生成技术的应用案例和演示,以证明其潜力和效果,吸引更多业务与用户进行合作。”
而基于腾讯混元的落地经验,他们希望构建 B 端、C 端之间的反馈循环,“ 我们尝试从 B 端渗透 C 端,先瞄准 B 端的场景,因为 B 端是主要的 3D 消费途径,立足于基础模型瞄准 B 端的实际应用需求,我们也逐渐弥补了没有覆盖到的 3D 矩阵能力。在满足了 B 端使用需求的前提下,我们开始探索 C 端的一些应用场景,通过 C 端的数据积累与反馈闭环,持续验证市场需求,可以再反哺回 B 端场景完成价值深化。”
随着业余爱好者的社区活跃度愈发高涨,当前,游戏领域的 AI 3D 生成的用户、创作者、开发者等角色界限逐渐模糊。
腾讯混元表示也希望顺应这个趋势,用开源工具进一步助力用户和开发者参与进来。不仅是游戏开发者,腾讯混元 3D 的开源还吸引了工业设计师、具身智能研究者等多方参与,推动技术从游戏扩展至自动驾驶、影视制作等场景。
提及腾讯混元 3D 开源的初衷,腾讯混元表示:“在 3D 生成领域,此前一直缺乏高质量的开源基础模型,导致学术研究与工业应用之间存在断层。我们也很重视用户反馈,例如社区提出的轻量版部署、加速、多视图生成、贴图优化、减面等需求已融入 Hunyuan3D 2.0 并开源。”
“ 下一步计划,将继续围绕生成质量和功能性展开。”
腾讯混元没有食言,新发布的 v2.5 版本更新恰好带来了生成质量的提升。
在此,知危也和各位玩家、社区开发者继续期待一波腾讯混元 3D 未来的新成果。