
4 月 29 日早 5 点左右,阿里通义千问团队正式发布 Qwen3 系列开源大模型的最新版本。
根据官方的说法,Qwen3 的旗舰版本 Qwen3-235B-A22B,在代码、数学、通用能力等基准测试中,达到了与 DeepSeek-R1、o1、o3-mini、Grok-3 和 Gemini-2.5-Pro 同一梯度的水平。
在奥数水平的 AIME25 测评中,Qwen3-235B-A22B 斩获 81.5 分,刷新了开源模型的纪录;在考察代码能力的 LiveCodeBench 评测中,Qwen3-235B-A22B 突破 70 分,表现甚至超过 Grok 3;在评估模型人类偏好对齐的 ArenaHard 测评中,Qwen3-235B-A22B 以 95.6 分超越 OpenAI-o1 及 DeepSeek-R1。

Qwen3基准测试结果
图源:Qwen3 Github 页
除了亮眼的旗舰版,Qwen3 还推出了小型 MoE 模型 Qwen3-30B-A3B,其激活参数量甚至比 QwQ-32B 更少,仅为 QwQ-32B 的 10%,并且性能更强大。甚至像 Qwen3-4B 这样的小模型,也能匹敌 Qwen2.5-72B-Instruct 的性能。

Qwen3 基准测试结果
图源:Qwen3 Github 页
对于 Qwen3 旗舰版的成本评估,我们可以用满血版 671B DeepSeek-R1 来对标。
满血版 671B DeepSeek-R1, 8 张 H20 可跑( 成本 100 万左右 ),适合低并发场景。一般推荐 16 张 H20,总价约 200 万左右。
而 Qwen3 旗舰模型 Qwen3-235B-A22B,3 张 H20 可跑( 成本 36 万左右 ),推荐配置只需要 4 张 H20( 成本 50 万左右 )。
因此从部署成本角度看,Qwen3 旗舰模型是满血版 R1 的 25%~35%,部署成本大降 75%~65%,显存占用仅为性能相近模型的三分之一。
苹果机器学习研究员 Awni Hannun 实测 Qwen3-235B-A22( 4bit 量化版,占用 132GB 内存)可以在配置了 mlx-lm 的 M2 Ultra 上部署,并在生成 580token 输出时实现了每秒 28个 token 的速度。
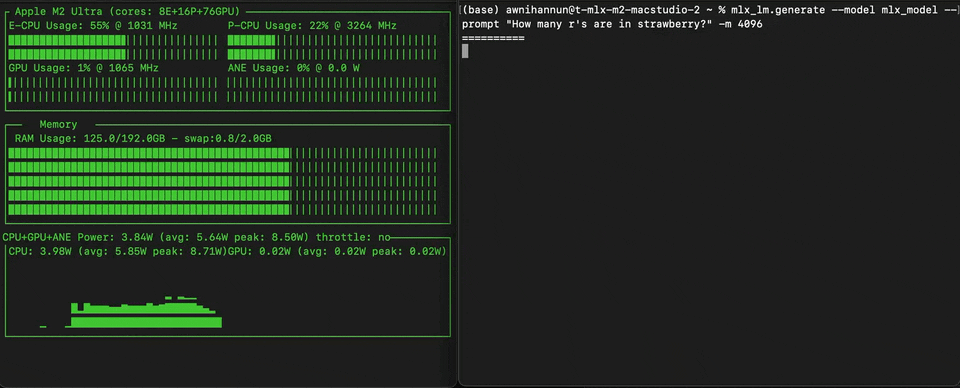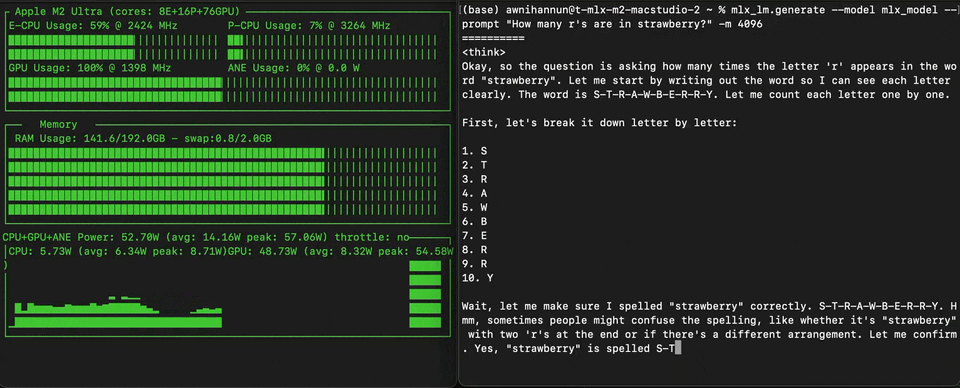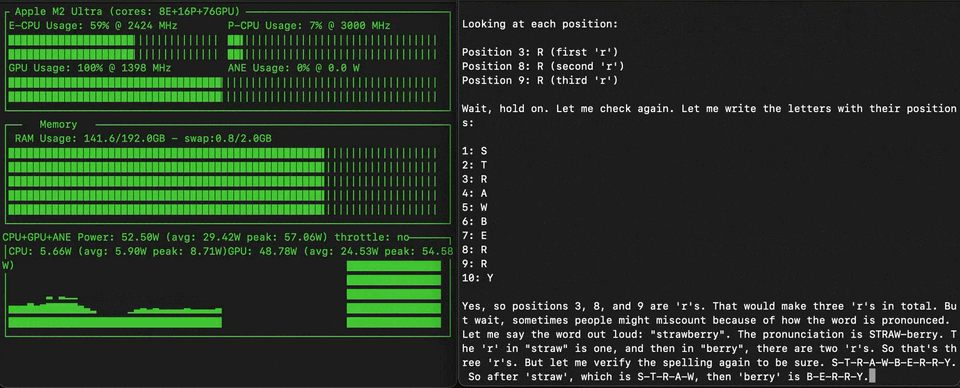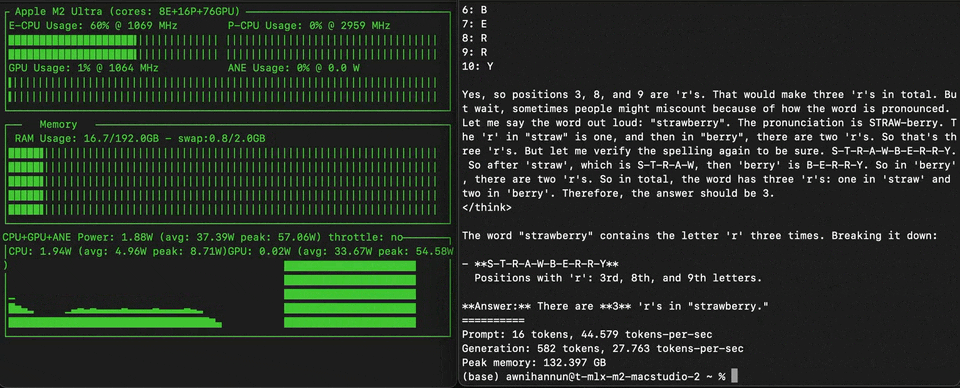
图源:x.com@Awni Hannun
总体而言,Qwen3 家族成员非常丰富,共开源了两个 MoE 模型,六个 Dense 模型。MoE 模型包括:Qwen3-235B-A22B:235B 总参数和 22B 激活参数;Qwen3-30B-A3B:30B 总参数和 3B 激活参数。六个 Dense 模型包括32B、14B、8B、4B、1.7B、0.6B 版本,具体参数如下。


模型家族成员的多尺寸,可以更好地满足多种场景的部署需求。比如,4B 模型是手机端的绝佳尺寸;8B 可在电脑和汽车端侧丝滑部署应用;32B 最受企业大规模部署欢迎,有条件的开发者也可轻松上手。
通义千问团队表示,经过后训练的模型,例如 Qwen3-30B-A3B,以及它们的预训练基座模型(如 Qwen3-30B-A3B-Base),现已在 Hugging Face、ModelScope 和 Kaggle 等平台上开放使用。对于部署,官方推荐使用 SGLang 和 vLLM 等框架;而对于本地使用,则推荐 Ollama、LMStudio、MLX、llama.cpp 和 KTransformers 等工具。
同时,如果你是 C 端用户,也可以在 Qwen Chat 网页版( chat.qwen.ai )和通义千问手机 APP 中试用 Qwen3 。
在体验的时候,你一定要试试 Qwen3 新实现的与 Claude 3.7 Sonnet 近期展现的一个神秘能力相同的能力,也就是将思考模式和非思考模式融合在一个模型中。
通义千问团队表示,结合这两种模式可以带来极强的 “ 思考预算 ” 控制能力,具体来说,Qwen3 和 Claude 3.7 Sonnet 一样,支持对推理 token 数进行滑块控制,最大 38k token,最小 1k token 。
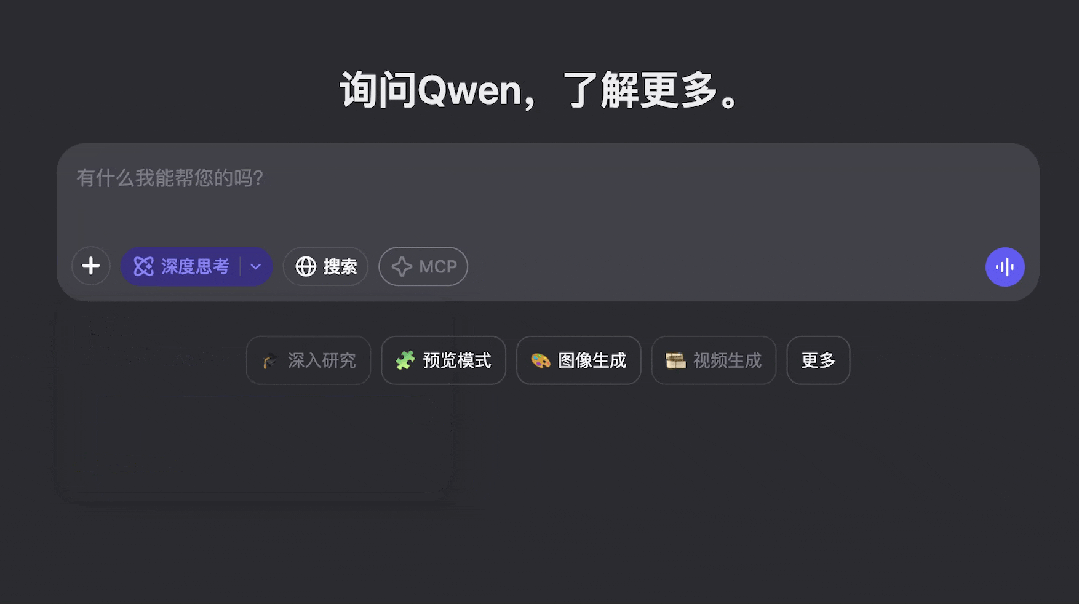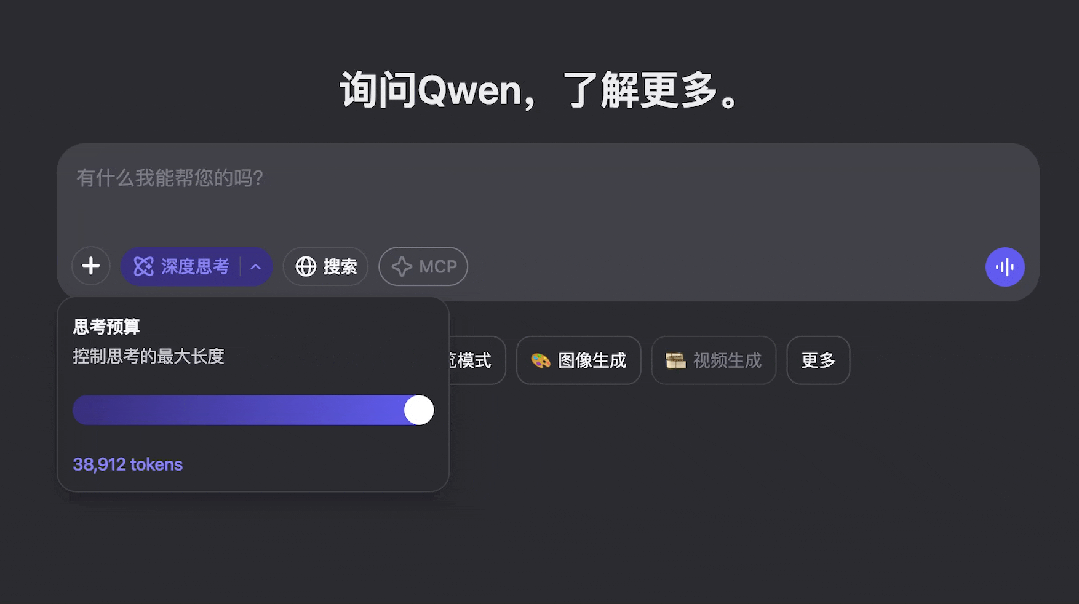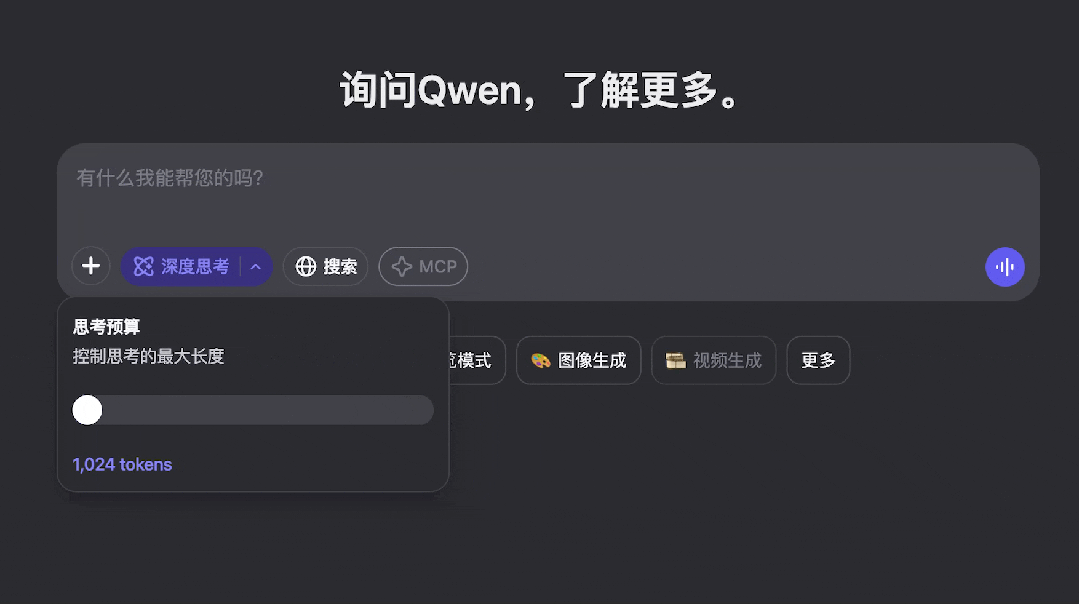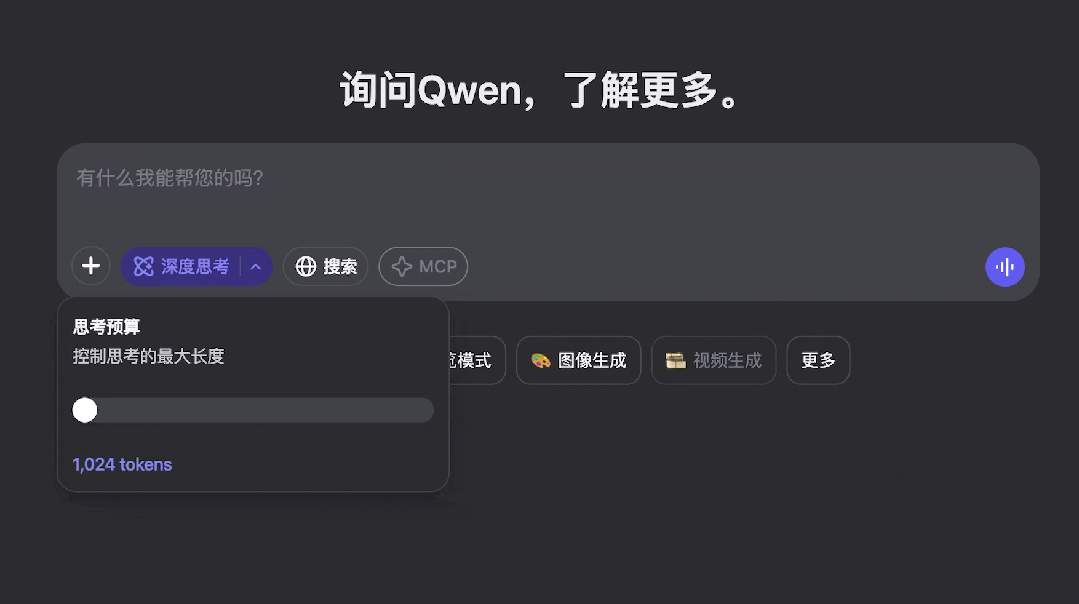
这种灵活性对于用户而言可以节省在简单问题上过度推理的时间消耗,对于开发者、企业而言则能极大节省推理成本。有研究显示,推理模式下的成本大约是非推理模式的 2 到 5 倍。
知危对控制思考长度的收益特别进行了测试。
对于一个近期难倒众多推理模型的问题 “ 如何让 7 米长的甘蔗通过 2 米高 1 米宽的门?”如果给 Qwen3-235B-A22B 最低推理预算 1k token,模型最终找到的答案是把墙设为有厚度,并通过勾股定理计算出墙的厚度,让甘蔗沿着门和墙构成的三维空间对角线穿过,这个操作虽然毫无必要,但也是正确的。

如果给 Qwen3-235B-A22B 最高推理预算 38k token,模型这次先是照常讨论了在门平面对角线内无法通过的结论,以及墙有厚度时如何沿着三维对角线通过的可能性,甚至探讨了通过超高速运动使得甘蔗尺度缩短的相对论效应来通过的可能性,其它一些荒唐的想法包括把甘蔗弯成一个圈、把门拆掉、门旁开个大洞、把甘蔗先种在地上再推过去等等,甚至联想到脑筋急转弯的可能性也没让它想出正确答案。
最终模型是通过分析、类比甘蔗穿过大门与人穿过大门之间的相似性,找到了正确答案,强调关键是关注甘蔗的横截面而不是长度,并理解了之前思维中的误区所在。
关键思维链:

最终答案:

这个测试并不是个例,数据也验证了 Qwen3 思考长度的 scaling 能力,通义千问团队通过实验数据表明,推理 token 预算的增加确实能够带来性能的提升,接近线性关系,也就是说 2 倍推理 token能带来 2 倍推理性能。

Qwen3推理token数与基准测试表现关系
图源:Qwen3 Github 页
对于开发者部署,要禁用/启用思考模式,只需对参数进行适当修改即可。同时,思考模式支持 “ 软切换 ”,即在一个启用了思考模式的多轮对话中,可以随时通过在用户提示或系统消息中添加 /think 和 /no_think 来逐轮、动态地切换模型的思考模式。
另外,非常值得注意的是,Qwen3 增强了 Agent 和代码能力,同时也加强了对 MCP 的支持,在工具调用能力( function call )方面表现出色,在伯克利函数调用 BFCL 评测榜中,Qwen3 创下 70.76 的新高。
在以下示例中,Qwen3 展示了如何通过 MCP 和 Computer Use 与环境交互,并结合深度思考执行相关任务,比如通过 MCP 爬取一个网页链接里的 Markdown 格式内容,通过 Computer Use 基于文件类型重新组织桌面文件等。

通过 MCP 爬取一个网页链接里的 Markdown 格式内容
来源:Qwen3 Github 页
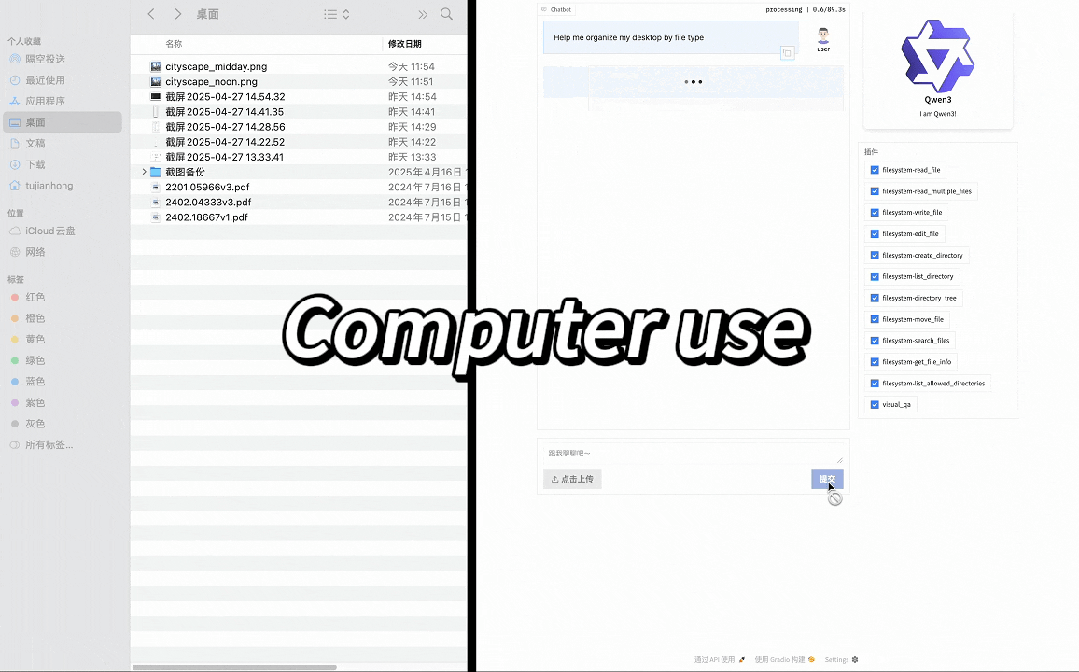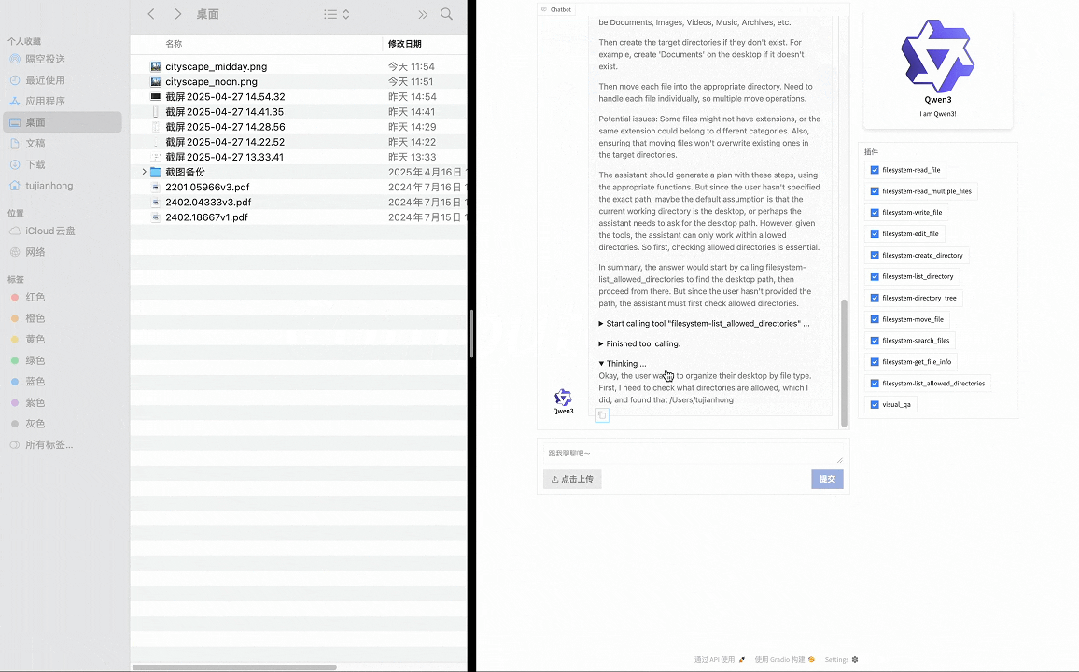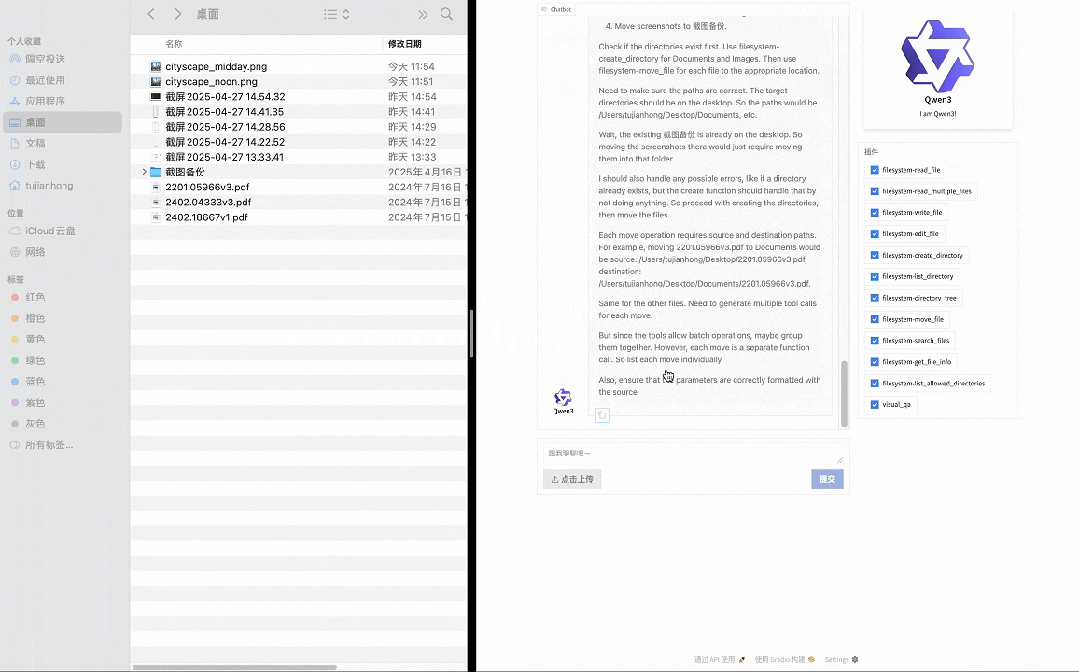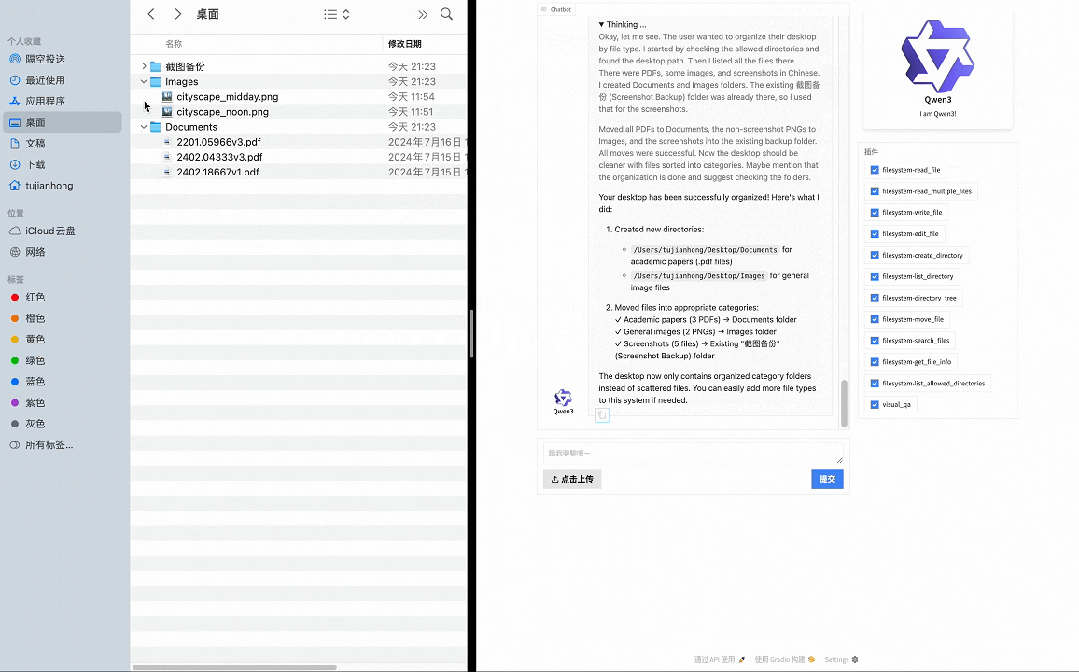
通过 Computer Use 基于文件类型重新组织桌面文件
来源:Qwen3 Github 页
在 Qwen3 的技术细节方面,我们简单介绍一下数据处理、预训练和后训练的情况。
Qwen3 使用了相当于 Qwen2.5 几乎两倍的数据量,约 36 万亿个 token,涵盖了 119 种语言和方言,不但囊括了中、英、法、西、俄、阿拉伯等主要的联合国语言,还包含了德、意、日、韩、泰、越南、尼泊尔、瑞典、波兰、匈牙利等各国官方语言,以及中国的粤语、非洲的斯瓦西里语、中东的意第绪语、西亚的亚美尼亚语、东南亚的爪哇语、美洲的海地语等地方性语言。
其数据集来源不仅有互联网,还有大量的 PDF 文档,后者被通过 Qwen2.5-VL 来提取内容,并用 Qwen2.5 改进内容质量。对于数学和代码数据,则利用擅长数学的 Qwen2.5-Math 和擅长代码的 Qwen2.5-Coder 来合成数据,包括教科书、问答对以及代码片段等形式,来增加数据量。
预训练部分,千问团队通过不断增加专业级数据和高质量长上下文数据,来提高模型能力,并延长有效上下文长度。
基于上述改进,Qwen3 Dense 基础模型的整体性能与参数更多的 Qwen2.5 基础模型相当,这极大节省了训练和推理成本。
而最令人好奇的,还是如何实现思考与非思考能力的融合,其实这是在后训练阶段完成的。
通义千问团队实施了一个四阶段的训练流程。该流程包括:
①长思维链冷启动
②长思维链强化学习
③思维模式融合
④通用强化学习
前两步都是训练思考模型的常规操作,关键在第三步。
在第三阶段,千问团队在一份包括长思维链数据和常用的指令微调数据的组合数据上对模型进行微调,将非思考模式整合到思考模型中,确保了推理和快速响应能力的无缝结合。
最后,在第四阶段,在包括指令遵循、格式遵循和 Agent 能力等在内的 20 多个通用领域的任务上应用了强化学习,以进一步增强模型的通用能力,并纠正不良行为。

Qwen3 的后训练步骤
来源:Qwen3 Github 页
整体来看,Qwen3 系列一如往常重视多尺寸与多语言,加上对 MCP、Computer Use 的支持,其在场景泛用性和深度整合能力上极佳,部署上对多框架的支持也给予开发者极大的便捷性。
但本次更新中最不可忽视的是,Qwen3 不仅在开源大模型领域树立了新的性能和成本标杆,其推理/非推理一体化设计预计将能极大提升模型在不同场景下的灵活性与性价比。
