SelfCite 提出了一种新颖的自监督方法,通过上下文消融技术和自监督奖励机制,提升大型语言模型 (LLM) 对上下文
SmolLM2 采用创新的四阶段训练策略,在仅使用 1.7B 参数的情况下,成功挑战了大型语言模型的性能边界:在 MML
本文介绍了一种名为 Diffusion-DPO 的方法,该方法改编自最近提出的直接偏好优化 (DPO)。DPO 作为 R
随着大型语言模型(LLM)规模和复杂性的持续增长,高效推理的重要性日益凸显。KV(键值)缓存与分页注意力是两种优化LLM
Transformer 架构因其强大的通用性而备受瞩目,它能够处理文本、图像或任何类型的数据及其组合。其核心的“Atte
STAR (Spatial-Temporal Augmentation with Text-to-Video Model
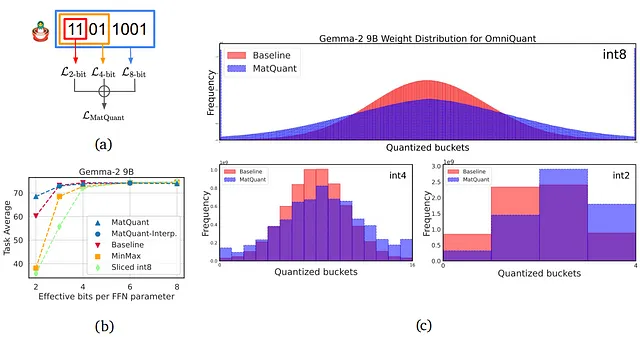
本文将介绍 Google DeepMind 提出的 Matryoshka 量化技术,该技术通过从单个大型语言模型 (LL
作为早期时间序列基础模型之一,Salesforce 开发的 MOIRAI 凭借其出色的基准测试性能以及开源的大规模预训练
大型语言模型 (Large Language Models, LLMs) 的发展日新月异。从最初的简单对话系统,到如今能
本文系统性地阐述了大型语言模型(Large Language Models, LLMs)中的解码策略技术原理及其实践应用
强化学习(Reinforcement Learning, RL)已成为提升大型语言模型(Large Language M
当前的大型语言模型在处理长序列文本时面临挑战。主要的瓶颈在于注意力机制,它将文本处理为单词(或 tokens)序列。注意
近端策略优化(Proximal Policy Optimization, PPO)算法作为一种高效的策略优化方法,在深度
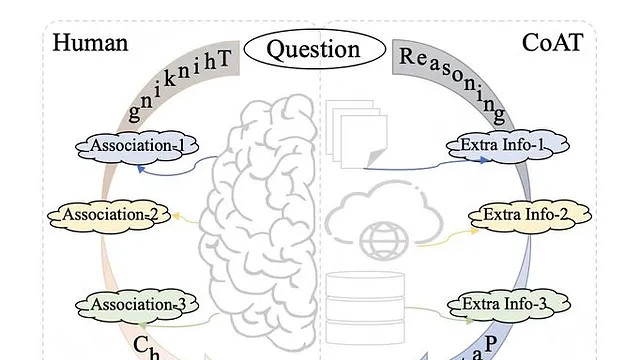
研究者提出了一种新的关联思维链(Chain-of-Associated-Thoughts, CoAT)方法,该方法通过整
在众多时间序列模型中,SARIMA(seasonal autoregressive integrated moving
本文介绍 DeepSeek-TS,该框架受到 DeepSeek 中高效的多头潜在注意力(MLA)和群组相对策略优化(GR
在人工智能(AI)和强化学习(RL)领域的发展进程中,长期记忆维持和决策优化一直是核心技术难点。传统强化学习模型在经验回
大语言模型(LLM)评估系统在生成思维链(Chain-of-Thought, CoT)序列时,需要系统地捕捉评估过程中的
DeepSeek-R1 通过创新的训练策略实现了显著的成本降低,同时保持了卓越的模型性能。本文将详细分析其核心训练方法。
在现代科学计算和数据分析领域,数据降维与压缩技术对于处理高维数据具有重要意义。本文主要探讨两种基础而重要的数学工具:Ka
签名:提供专业的人工智能知识,包括CV NLP 数据挖掘等